【機械学習】初心者がKaggleのtitanicで勉強してみた(前処理編)
初心者が Kaggle の Titanic をやってみた 2 回目前処理編やります!
【機械学習】初心者が Kaggle の titanic で勉強してみた
前回は、データを眺めて、データの相関を確かめた。
今回は、それらの情報から実際にデータを処理していく。
前処理
※ 自分の理解です。
前処理とは、与えられたデータを使ってモデルを作成する前にデータを適した形に直す処理のこと。
参考書を読むと、もっと詳しく体系的に書かれているが、ざっくり説明するとこんな感じだろうと思う。
では、なぜ前処理をするか?
一般的にデータは汚いからです!
汚いとは、言い換えると解析に適さない形、不要なものがたくさん含まれているということである。
例えば、今回でいうと欠損値であったり外れ値であったりといろいろある。
ちなみにこの Titanic のデータはとてもとても綺麗なデータです。
欠損値を補完して、カテゴリ変数を数値化したらモデルに入れられそう。
方針
前処理をやるにあたって今回は前処理パイプラインというものを試してみる。
パイプラインを使わずにもできるのだが、のちに再利用することや特徴量選択のことを考えて、パイプラインを使用する。
前処理:数値
まずは、数値データの処理からやっていく。
そこでデータから数値データのみを取得するクラスを定義する。
from sklearn.base import BaseEstimator, TransformerMixin
## データフレームから指定したタイプの列を抽出
class DataFrameExtracter(BaseEstimator, TransformerMixin):
# dataTypeはnumberかobject
def __init__(self, dataType):
self.dataType = dataType
# 変換式を計算
def fit(self, X, y=None):
return self
# 変換式を用いてデータを変換
def transform(self, X, y=None):
return X.select_dtypes(include=[self.dataType])1 行目のBaseEstimator, TransformerMixinを import することでfit_transformなどのメソッドが継承される。
このfit_transformが継承されるとなぜ嬉しいかというと、のちに定義するパイプラインはfit_transformメソッドを順次呼び出していくからである。
なので、↑ のコードではfit_transformを省略している。
入力は pandas の DataFrame を想定していて、select_dtypesで指定したタイプを取り出すことができる。
pandas は数値型int、floatなどをまとめてnumberとして指定してとりだせるのでマジ便利。
これで数値のみの列を取り出せる。次は、取り出した数値列のうち不要なものを削除するクラスを定義する。
# 指定した列を削除
class DropAttributes(BaseEstimator, TransformerMixin):
def __init__(self, dropList):
self.dropList = dropList
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
return X.drop(self.dropList, axis=1)これも pandas の drop メソッドで指定した列を削除できる。
ちなみに、列を削除するのはあまり安易にやらないほうがいいらしい。
不要だと思っていても実は重要だったりといったことが起こる可能性がある。
今回は、早く結果までたどり着きたいので、相関が低いやつはてきとうに落としていく。
不要な列も取り除いたので、次は欠損値をうめるクラスを定義する。
# 欠損値の補完(中央値、平均などを用いる)
class FillNa(BaseEstimator, TransformerMixin):
def __init__(self, valueType='median', columns=[]):
self.valueType = valueType
self.columns = columns
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
if self.valueType == 'median':
for col in self.columns:
if X[col].dtype != 'object':
X[col] = X[col].fillna(X[col].median())
return X
elif self.valueType == 'mean':
for col in self.columns:
if X[col].dtype != 'object':
X[col] = X[col].fillna(X[col].mean())
return X欠損値の扱い方には自分が知る限りだと次の方法がある。
- 欠損値の補完に中央値を用いる
- 欠損値の補完に平均値を用いる
- 欠損値のある行を削除する
なんとなく 2 番目が良さそうだと思ったが、参考書や他の人のコードでは中央値を用いていることが多い。
理由は、平均だと外れ値がある場合に、その値に引っ張られるからではないかと考えている。
これはあとでしっかり検証したいと思う。
前処理:カテゴリ変数
データの中には男女やなにかの種類(商品名)など、複数の数値で表現できないカテゴリが存在しているものがある。
それらは当然モデルに入力できないので、なんらかの数値に変換する。
よく使用されるのがダミー変数化だ。
今回はこのダミー変数化を行うクラスを作る。
# カテゴリ変数をダミー変数化
class DummyCat(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X = pd.get_dummies(X)
return Xなんとこれだけで実装できてしまう。
これも pandas のメソッドでget_dummiesを用いることで実現できる。
しかも、このメソッドの賢いところは、列名にカテゴリ名を含めてくれることだ。
前処理パイプライン
ここまでで必要なクラスの定義ができたので、実際にパイプラインを作っていく。
rom sklearn.pipeline import Pipeline
import numpy as np
# いらないと思われる列を指定
dropNumList = ['PassengerId', 'Survived']
# 数値列に対して欠損値の補完などを行う
num_pipeline = Pipeline([
('selector', DataFrameExtracter(dataType='number')),
('dropAtt', DropAttributes(dropList=dropNumList)),
('fillNa', FillNa(valueType='median', columns=['Age'])),
])
# 前処理済み数値データ
num_data = num_pipeline.fit_transform(train_data)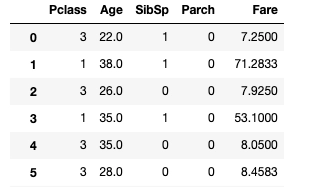
このように呼び出したい順番に各クラスを記述していく。
結果をみるとdropNumListに書かれた列は削除されていることがわかる。
欠損値についても以下のようになくなっていることがわかる。

カテゴリ変数についてもどうように処理していく。
# いらないと思われるカテゴリ列を指定
dropCatList = ['Name', 'Ticket', 'Cabin']
# オブジェクトタイプん列に対してダミー変数化などを行う
cat_pipeline = Pipeline([
('selector', DataFrameExtracter(dataType='object')),
('dropAtt', DropAttributes(dropList=dropCatList)),
('dummy', DummyCat()),
])
# 前処理済みカテゴリ変数
cat_data = cat_pipeline.fit_transform(train_data)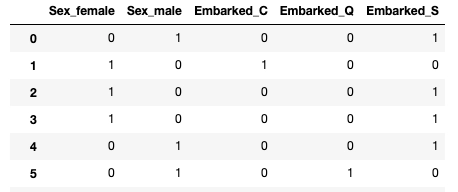
結果からうまくカテゴリごとに数値化できたことが確認できる。
(男女は分けなくてもいい説)
ラストはこの二つを結合させる。
from sklearn.pipeline import FeatureUnion
# 二つのパイプラインを結合する
full_pipeline = FeatureUnion(transformer_list=[("num_pipeline", num_pipeline), ("cat_pipeline", cat_pipeline)])
cleaned_data = full_pipeline.fit_transform(train_data)
columns = list(num_data.columns) + list(cat_data.columns)
# arrayと列の対応関係を保持
map_columns = {}
for idx, key in enumerate(columns):
map_columns[idx] = keyこれで二つのパイプラインを結合して一つにできた。
ただ、もうちょっとまとめたい気もしている。
結局、二つのパイプラインをいちいち定義する工程が入るので、それもメッソド化するクラスを作っても良さそう。
得られたcleaned_dataは numpy.ndarray の型に変換されている。
これは、以降で用いる各手法の入力がベクトルを指定しているためである。
さて、これであとはデータをモデルにいれるだけの状態にできた!
まとめ
今回は前処理について書いた。
前処理は奥が深く自分が書いたような単純な事ばかりではなさそう。
ただ、個人的には最初から深く立ち入ってもなんのためにやっているかわからなくなるので、まずは先に進むことを優先してみた。
実際、ぽんぽん前に進むと学習意欲が湧いてくる。
次は一番面白いと思われるモデル検証編をやります!
参考書籍・サイト等は前回と同様です!