
最新の記事
論文まとめ2026-07-25
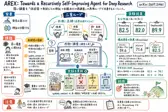
AREX: Towards a Recursively Self-Improving Agent for Deep Research
深い調査は、検索回数を増やすより「検証済みの進捗を残し、未解決の条件だけを調べ直す」方が強くなるのか。
#論文まとめ#AIエージェント読了 8分

論文まとめ2026-07-24
PRO-LONG: Programmatic Memory Enables Long-Horizon Reasoning
長い履歴は要約して縮めるべきなのか、それとも完全に残して必要な時だけコードで読めばよいのか。
#論文まとめ#エージェント記憶読了 8分

論文まとめ2026-07-23
SkillSight: Seeing Through Shared Descriptions for Accurate Skill Retrieval
似たスキルが増えたとき、検索はなぜ定型文に引っ張られ、本当に必要な能力を見失うのか。
#論文まとめ#エージェントスキル読了 8分
論文まとめ2026-07-22
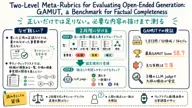
Two-Level Meta-Rubrics for Evaluating Open-Ended Generation: GAMUT, a Benchmark for Factual Completeness
事実誤認の少ない長文回答でも、肝心な情報が抜ける。自由回答の「必要な内容が揃っているか」をどう評価するのか。
#論文まとめ#評価読了 8分
論文まとめ2026-07-21
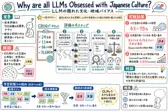
Why are all LLMs Obsessed with Japanese Culture? On the Hidden Cultural and Regional Biases of LLMs
文化について正しく答えられるLLMでも、曖昧な場面では一部の国だけを「標準的な文化」として持ち出していないか。
#論文まとめ#評価読了 8分
論文まとめ2026-07-21
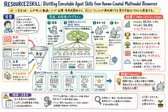
RESOURCE2SKILL: Distilling Executable Agent Skills from Human-Created Multimodal Resources
人間向けの動画やコードを、AIエージェントが実行できるスキルへ変えるには何が必要か。
#論文まとめ#エージェントスキル読了 8分

論文まとめ2026-07-18
The Severance Problem: LLMs are Unaware of the Person Beyond the Prompt
個人向けAIは、ユーザーについて覚えるほど理解を深めるのか。それとも、まだ知らないことを忘れて過信するのか。
#論文まとめ#エージェント記憶読了 8分

論文まとめ2026-07-17
Bridge Evidence: Static Retrieval Utility Does Not Predict Causal Utility in Multi-Step Agentic Search
現在の質問には役立たなく見える文書が、次の検索を導くことで探索全体には不可欠になる。その価値をどう測ればよいのか。
#論文まとめ#エージェント型検索読了 8分

論文まとめ2026-07-16
Harness Handbook: Making Evolving Agent Harnesses Readable, Navigable, and Editable
エージェントの変更依頼が語る「挙動」と、リポジトリ内に分散した実装をどう結びつければ、探索量を減らしながら変更漏れを防げるのか。
#論文まとめ#エージェントハーネス読了 8分
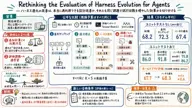
論文まとめ2026-07-15
Rethinking the Evaluation of Harness Evolution for Agents
ハーネス進化の点数上昇は、本当に再利用できる設計改善なのか、それとも同じ課題で試行回数を増やした効果なのか。
#論文まとめ#エージェントハーネス読了 8分

論文まとめ2026-07-14
Always-On Agents: A Survey of Persistent Memory, State, and Governance in LLM Agents
長く動くAIエージェントの記憶を、便利な検索機能ではなく、権限・削除・監査・復旧まで含む永続状態としてどう管理するか。
#論文まとめ#エージェント記憶読了 8分
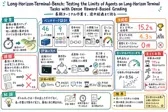
論文まとめ2026-07-13
Long-Horizon-Terminal-Bench: Testing the Limits of Agents on Long-Horizon Terminal Tasks with Dense Reward-Based Grading
長い作業を最後の合否だけで採点すると、エージェントがどこまで進み、どこで止まったかを見失わないか。
#論文まとめ#エージェントハーネス読了 8分