自然言語処理:BERTでSHAPを使用した説明性可視化
超雑記事です。
機械学習モデルの説明を与える手法として SHAP があります。
今回はこの SHAP を自然言語処理の機械学習に使用してみたいと思います。
使用するモデルは BERT です。
SHAP の説明はだいぶ大雑把なので SHAP の正確な理解をしたい場合は他の書籍やサイトを閲覧することをお勧めします。
SHAP は何を見てる?
model の出力に対する各特徴量の寄与度を計算しています。何を見ているか、と言うと入力の特徴量とモデル出力の関連でしょうか。
計算に使用されるのは学習済みのモデルとデータのみです。
SHAP はローカル説明性の手法とも言われています。(1 入力に対して、その入力のどこが重要だったかを提示するため)
より詳細な説明はDataRobot さんの記事が参考になります
BERT で SHAP を使う方法
早速使ってみます。
SHAP は Python で気軽に使うことができます。
使用するデータは livedoor です。
今回使用するファインチューニング済みの BERT は、事前学習済みモデルにcl-tohoku/bert-base-japanese-v2、ファインチューニング時は livedoor データのうち後述する 4 つのラベルのみを使用しました。
以下がコードです。全て載せると冗長なので、重要な部分の抜粋です。 詳しいことはSHAP: Emotion classification multiclass exampleに記載されてます。
from transformers import pipeline
import shap
# ファインチューニング済みBERTのロード
model = BertForSequenceClassification.from_pretrained(settings.pretrained_model, num_labels=4)
tokenizer = BertJapaneseTokenizer.from_pretrained(
"cl-tohoku/bert-base-japanese-v2",
#do_subword_tokenize=False,
#mecab_kwargs={"mecab_dic": None, "mecab_option": "-d 'C:\mecab-unidic-neologd'"
)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
pred = pipeline("text-classification", model=model, tokenizer=tokenizer, device=device, return_all_scores=True)
# label_mapはlivedoorのラベルと学習時のラベルをマッピングさせるものです
explainer = shap.Explainer(pred, output_names=list(label_map.keys()))
# filterd_test_dfは4つに絞ったlivedoorデータのdataframe
# 512は今回のBERTの設定で指定したトークンの長さです。今回は3文書をテスト用にリスト化
input_text = [text[:512] for text in filterd_test_df.text[:3].tolist()]
shap_values = explainer(input_text)
shap.plots.text(shap_values)以下が 1 つ目の文書の結果です。正解ラベルが sports に対して、スポーツ系の単語の寄与度が高いことがわかります。 ただ、日付の関連度が高いのは謎ですね。データを確認する必要がありそうです。
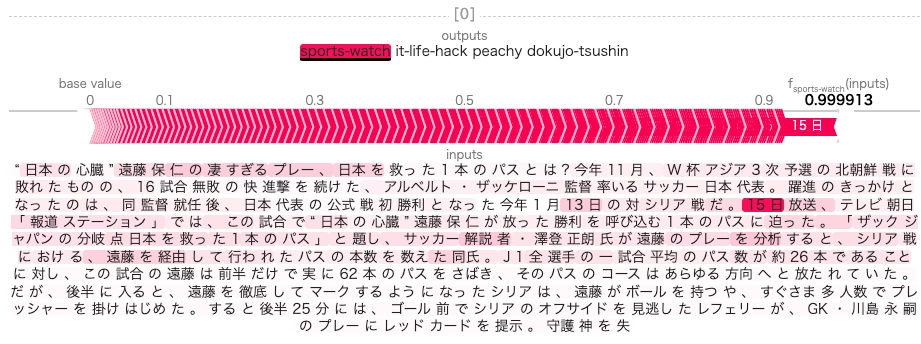
試しにネットで拾った最近のスポーツに関する話題を入力してみました。
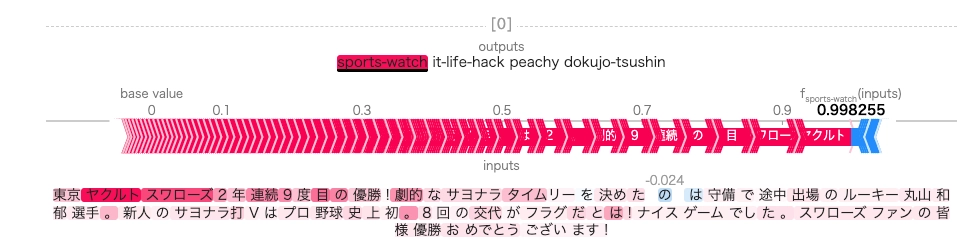
やはりそれっぽい単語には着目してるようです。もしかして、数字が重要になってるのは点数とかが記事中に多く含まれるからなのかもしれない。
使った感想
SHAP を使用することで、なんとなくそれっぽい説明性が得られることがわかった。また SHAP 自体はかなり使いやすい。
一方で、SHAP で得られた結果の読み取り方がいまいちなのか「ん?」と思う結果もある。
加えて、 4 ラベルの結果を出力しているつもりなのだが、2 つ分のラベルの結果のみで、残り二つはどの単語も全く結果に貢献していないことになっている。 ライブラリ理解も必要。
ハマったところ
shap.plots.textの計算が終わらず、何故だろうと思っていたら以下の部分で入力が文章ではなく単語ごとのリストになっていた。
shap_values = explainer(input_text)エラーにはならないので待ち時間分を溶かした