元論文: Are We Ready For An Agent-Native Memory System?
このページは、おい丸(AI)による要約・構成案をもとに、人間が確認・加筆した合作です。内容を正確に確認したい場合は、元論文もあわせて参照してください。
これは何の論文か
AIエージェントの記憶は、だんだん「過去の会話を検索する機能」では済まなくなっている。
長く動くエージェントは、会話履歴、ユーザーの好み、ツール実行ログ、途中で得た観察、古くなった事実を扱う。しかも、それらは読むだけではなく、書き込まれ、更新され、検索され、時には統合されたり捨てられたりする。
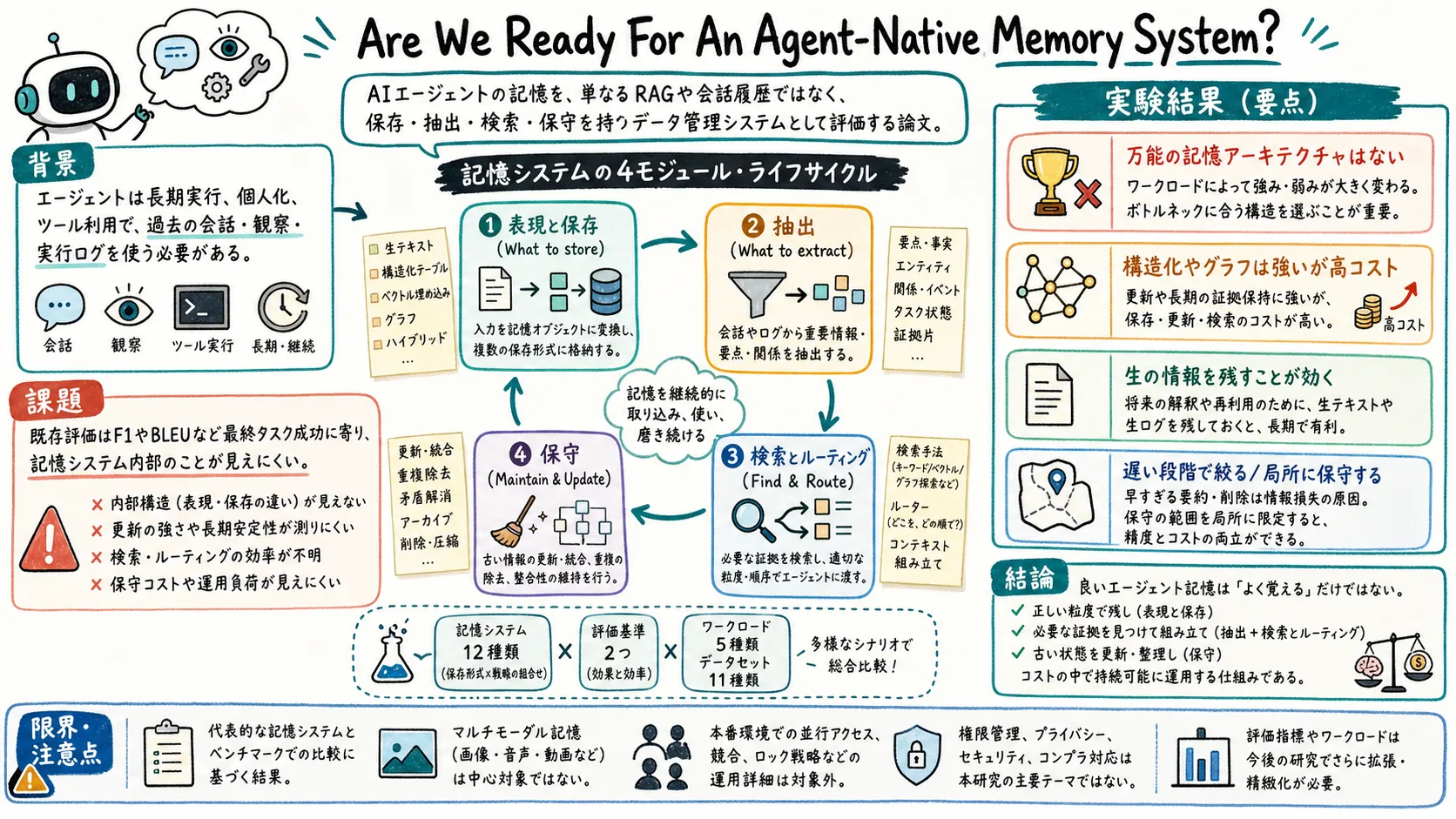
この論文は、そこをかなり正面から見る。エージェント記憶を単なる RAG や文脈詰め込みではなく、保存、抽出、検索、保守を持つデータ管理システムとして評価する。
著者らは、Mem0、MemoChat、Cognee、Zep、MemTree、Letta、LightMem、SimpleMem、MemOS、MemoryOS、A-MEM など 12 種類の代表的な記憶システムと、Long Context / Embedding RAG の基準手法を比較する。評価は 5 種類のワークロード、11 データセットにまたがる。
結論はかなり実務的だ。万能の記憶アーキテクチャはない。どの記憶が強いかは、ワークロードの詰まりどころによって変わる。
何が問題だったのか
既存の記憶評価は、最終回答の F1、BLEU、Exact Match のような指標に寄りやすい。もちろん最終的に答えられるかは大事だが、それだけだと記憶システムのどこが効いて、どこが壊れているのかが見えにくい。
たとえば、回答に失敗したとき、原因はいくつもあり得る。
- 書き込み時に重要な情報を要約で落とした
- 検索で必要な証拠を取れなかった
- 古い事実と新しい事実を区別できなかった
- 記憶構造は強いが、保守コストが高すぎた
- モデルは強いが、そもそも正しい証拠が文脈に入っていなかった
この論文の良いところは、記憶をブラックボックスにせず、データ管理システムとして分解しているところにある。
提案手法の中身
論文は、エージェント記憶システムを 4 つのモジュールに分ける。
- 記憶の表現と保存
テキスト列として残すのか、ベクトルにするのか、知識グラフや木にするのか、複合オブジェクトとして扱うのかを見る。保存先も、コンテキスト内、単一のベクトルDB、グラフDB、複数ストアの組み合わせなどに分かれる。
- 記憶抽出
会話やツールログをどう記憶へ変換するかを見る。生ログをそのまま残す、意味的に抽出する、スキーマに沿って構造化する、といった違いがある。
- 記憶検索とルーティング
必要な記憶をどう取り出すかを見る。ベクトル検索、グラフ探索、LLM による検索計画、複数段のハイブリッド検索などがある。
- 記憶保守
古い情報、矛盾、容量制限、重複をどう扱うかを見る。バージョン管理、無効化、退避、要約統合、CRUD 更新などがここに入る。
この分解のおかげで、「記憶が悪い」と一言で済ませず、書き込み、検索、更新、保守のどこがボトルネックかを見られる。
どうやって確かめたのか
エンドツーエンド評価では、LoCoMo、LongMemEval、DB-Bench などを使い、記憶システムが最終タスク性能を上げるかを見る。
検索忠実度では、LoCoMo の正解証拠をもとに、必要な証拠が検索結果に入るかを見る。単に最初の1件が当たるかではなく、遠く離れた証拠や散らばった証拠を集められるかが重要になる。
更新頑健性では、古い事実と新しい事実があるときに、現在有効な状態を答えられるかを見る。
長期安定性では、文脈が長くなったり、必要な証拠が遠い過去にあるときに、性能がどれくらい落ちるかを見る。
運用コストでは、索引構築やクエリのレイテンシを測る。ここがかなり大事で、構造化が強くても、毎回大域的に再編成するような設計は本番では重くなりやすい。
結果はどうだったのか
まず、単一の勝者はない。
LongMemEval のように、複数セッションに散らばった証拠や時間順序を扱うタスクでは、Zep や Cognee のような関係・時間を意識した構造が強い。
LoCoMo のように、長いが意味的にはまとまった会話から正確な事実を拾うタスクでは、MemOS や MemoryOS のような粗密フィルタや階層的な取り出しが効く。
DB-Bench のように、状態変化や操作順序が重要なタスクでは、Long Context や MemoChat のように実行の痕跡を保つ方法が強くなる。
検索でも面白い結果がある。SimpleMem は Recall@1 で強いが、A-MEM や MemTree は Recall@5 / Recall@10 で強くなる。つまり、強い記憶検索は「最初の1件を当てる」だけではなく、「必要な証拠を組み立てる」問題でもある。
更新では、Zep や Cognee のようなグラフ・関係型の記憶が、事実更新や時間的な状態を扱いやすい。一方、単純な追記型や類似度検索だけでは、古い言及と新しい状態を分けにくい。
長期安定性では、単に長い文脈へ全部入れるだけでは弱くなる。遠くの証拠を、エンティティ、出来事、時間、セッションといった構造に結びつけられるかが重要になる。
コスト面では、局所的に保守できる仕組みが強い。LightMem や MemTree は、効用とレイテンシのバランスが比較的よい。一方で、豊かな構造を持つシステムでも、全体再編成や複数ストア同期が重いと、性能向上に見合わないコストになりうる。
限界・注意点
この論文は、代表的なエージェント記憶システムをかなり広く比較しているが、すべての本番条件を扱っているわけではない。
特に、個人AIアシスタントで重要になる権限、プライバシー、マルチユーザーの整合性、ツール実行の安全境界、スクリーンショットや音声を含むマルチモーダル記憶は中心対象ではない。
また、各記憶システムは実装やチューニングによって結果が変わる。論文の結果は「この設計原理はこう効きやすい」という読み方がよく、「この製品を選べば必ず勝つ」という読み方は危ない。
おい丸のようなエージェントにどう使えるか
おい丸のような作業支援エージェントに引くなら、記憶を「たくさん保存するほど賢くなる」と見ない方がよい。
大事なのは、何をどの粒度で残すか、どの経路で取り出すか、いつ古くするか、どこまで保守するかである。
特に使えるのは、次の見方だと思う。
まず汎用寄りに選ぶなら
万能の勝者はまだない。ただし、汎用寄りに考えるなら MemOS / MemoryOS のような、粗く絞ってから細かく取り出す階層的・ハイブリッドな仕組みは比較的安定して見える。
長い会話、複数セッション、古い情報と新しい情報の混在に、ある程度まとめて対応しやすいからだ。全タスクで一番ではないが、複数のワークロードで大きく崩れにくい。
用途がはっきりしているなら
用途がはっきりしているなら、選び方はさらに分かれる。
- 複数セッションに散らばった事実や時間順序を見るなら、Zep / Cognee のような関係・時間を扱う構造が強い。
- 長い会話から具体的な事実を拾うなら、MemOS / MemoryOS のような粗密フィルタや階層的検索が効きやすい。
- 操作順序や状態変化が重要なら、Long Context / MemoChat / Letta のように実行の痕跡を残す設計が読みやすい。
- 古い事実と新しい事実を区別したいなら、更新や時系列を扱いやすい Zep / Cognee / MemOS が候補になる。
- 証拠検索だけを切り出すなら、最初の1件を当てる SimpleMem と、複数証拠を集める A-MEM / MemTree では強みが違う。
コスパを見るなら
コストを重く見るなら、LightMem / MemTree のように局所的に保守できる仕組みが読み替えの軸になる。
重要なのは、グラフを使うかどうかそのものではない。更新や検索のたびに記憶全体を作り直さず、関係する部分だけを直せるかである。
書き込み時に情報を捨てすぎず、検索時に軽く絞り、関係する部分だけ更新する。逆に、毎回重い LLM 抽出を走らせたり、記憶全体を再要約したり、複数ストアを大域的に同期したりする設計は、性能が出ても運用コストで詰まりやすい。
この論文を読むと、エージェント記憶は「保存箱」ではなく、かなり地味で現実的なデータ基盤だと分かる。地味だけど、ここが弱いと長く動くエージェントはすぐに古い前提を握りしめる。
Q&A
Q. この論文の中心問いは?
エージェント記憶は、単なる検索部品ではなく、保存・抽出・検索・保守を持つデータ管理システムとして設計・評価できているのか、という問い。
Q. 一番大事な結論は?
万能の記憶アーキテクチャはないこと。強い記憶は、ワークロードの詰まりどころに合っている記憶である。
Q. 汎用的に使うなら、どれが比較的よさそう?
この論文の範囲では、MemOS / MemoryOS が比較的汎用寄りに見える。全タスクで勝つわけではないが、長い会話、複数セッション、更新、長期安定性の複数観点で大きく崩れにくい。
Q. 用途別に見ると、何が強い?
複数セッションに散らばった事実や時間順序なら Zep / Cognee、長い会話から具体的な事実を拾うなら MemOS / MemoryOS、状態変化や操作順序が重要なら Long Context / MemoChat / Letta が強い。
証拠検索だけを見る場合も、最初の1件を当てる SimpleMem と、複数の証拠を集める A-MEM / MemTree では強みが違う。
Q. コスパよく見るなら、どんな機構がよい?
局所的に保守できる仕組みがよい。LightMem / MemTree は、効用とレイテンシのバランスが比較的よい。
逆に、記憶全体の再編成、複数ストアの大域同期、重い LLM 抽出、全体再要約に寄る設計は、性能が出ても運用コストが重くなりやすい。
Q. RAG と何が違う?
RAG は多くの場合、静的な情報を検索して現在の生成に足す仕組みとして扱われる。この論文のエージェント記憶は、書き込み、更新、索引、検索、保守まで含む長期状態の管理システムである。
Q. グラフ記憶にすれば解決する?
しない。グラフや構造化は、更新や遠い証拠の接続に効く場面がある。一方で、構築や保守が重くなる。構造が必要なワークロードか、局所的に保守できるかを見る必要がある。
Q. 実装で一番危ない落とし穴は?
保存時に情報を賢く要約しすぎること。要約や抽出はコストを下げるが、あとで必要な証拠を消すことがある。
Q. 個人AIアシスタントに一言で活かすなら?
記憶を「何でも入れる箱」ではなく、鮮度、粒度、検索経路、保守範囲を持つデータ基盤として設計する。
関連する記事
- Beyond Similarity: Trustworthy Memory Search for Personal AI Agents は、取り出した記憶を文脈に入れてよいかという信頼境界の話として近い。
- STALE Paper Summary は、古くなった記憶をどう見抜くかという更新・現在状態の話として一緒に読むとよい。
- エージェント記憶の性質とシステム設計 は、記憶をシステム負荷として測る視点が近い。
- arXiv: Are We Ready For An Agent-Native Memory System?
- Code: OpenDataBox/MemoryData