AWS Lambdaを使ったツイート収集システム
以前書いたPython と Twitter API を利用したツイート収集方法では Twitter API を利用して特定のキーワードのツイートを収集する方法を紹介しました。
しかし、記事で述べたように API で取得できるのは7日前までのツイートのみです。
有料プランを使わずにより多くの情報を取得するには、日々検索を行い地道に集める必要があります。
そこで、AWS Lambda を利用して毎日決まった時間に Twitter API を叩くコードを作成します。
本記事で伝えたいことは以下の3つです。
- docker を使った lambda-uploader の使い方
- lambda から s3 への保存方法
- lambda のスケジュール実行
Docker を利用した AWS Lambda アップロード方法
AWS Lambda の簡単なアップロード方法については【AWS】python-lambda-local と lambda-uploader を使ってみたで書きました。この記事では、ローカルで docker を使わずに lambda-uploader を使用していました。
しかし記事のやり方ではコード内で numpy を用いると以下のようなエラーがでます(pandas を使ったコードだったので内部的に numpy が必要になるようです。)
Unable to import module 'lambda_handler': Missing required dependencies ['numpy']
どうやら普通にノート PC 上でやると lambda-uploader で作成される zip は Lambda に合った形式になっていないようです。
今回は amazonlinux2 上で使用するモジュールごと zip 化することで解決しました。
公式ドキュメントを読んだ感じでは、他にも解決方法がありそうです。わかりやすいところだと layer を使うという手があります。
参考 URL
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/lambda-deployment-package-errors/
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/python-package.html
さて、amazonlinux2 上で作業するには EC2 の AMI で選択すればいいのですが、いちいち EC2 を使うのも面倒なので Docker の amazonlinux2 イメージを利用します。
さらに Docker 上に Lambda のアップロード環境も構築します。
今回使用した作業フォルダの構成は以下になります。
.
├── Dockerfile
├── README.md
├── docker-compose.yml
├── script.sh
└── upload-files
├── event.json
├── lambda.json
└── lambda_handler.py
upload-files の中身は以前書いた記事の通りです。
使用した Dockefile はこんな感じです。
FROM amazonlinux:2
RUN yum install python3 -y
RUN yum install unzip -y
RUN pip3 install pip --upgrade
RUN pip3 install lambda-uploader python-lambda-local
RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
RUN unzip awscliv2.zip
RUN ./aws/install
WORKDIR /home/work
COPY ./upload-files/ /home/work
CMD ["/bin/bash"]
Docker で AWS CLI の認証情報を設定する
Docker で AWS CLI を利用するには aws cli のインストールの他に認証情報の設定が必要になります。
Docker 内でいちいち設定するのも大変なので、環境変数に設定してスクリプトで docker-compose を実行することにしました。
本当は${HOME}/.aws/をマウントしてやろうしましたが、うまくいきませんでした(うまくいくやり方が合ったら教えてください)。
作成したスクリプトファイルと docker-compose.yml は以下のようになりました。
version: '3'
services:
aws-cli:
build: .
tty: true
environment:
AWS_ACCESS_KEY_ID: ${AWS_ACCESS_KEY_ID}
AWS_SECRET_ACCESS_KEY: ${AWS_SECRET_ACCESS_KEY}
AWS_DEFAULT_REGION: ap-northeast-1
AWS_DEFAULT_OUTPUT: json
command: /bin/bash
region と default output は上記しか使う予定がないので決め打ちしてます。 スクリプトファイルは以下です。
#!/bin/bash
export AWS_ACCESS_KEY_ID="*************"
export AWS_SECRET_ACCESS_KEY="*************"
docker-compose build
docker-compose run aws-cli lambda-uploader --variables '{環境変数Key:Value}'
認証情報や Lambda で使用する環境変数は各々設定してください。
このようにスクリプトファイルにしておけば、スクリプトの実行で Lambda のアップロードが実行できます。
Twitter API で 1 日分のツイートを取得
以前の記事では、クエリに対して取得できるだけツイートを取得していました。しかしこのやり方では、毎日収集すると重複するデータが大量に発生するので1日分のツイートだけ収集するように書き換えます。
やり方は簡単です。API へ入力するクエリにsince:、until:のオプションを付加します。JSTの時間にも対応しているようなので以下のように日時を設定しました。
from datetime import datetime, timedelta, timezone
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
# 現在の日時
now = datetime.now(JST)
# 前日の日時
yesterday = now - timedelta(days=1)
# 日本時間の24時
now = " until:" + now.strftime('%Y-%m-%d_00:00:00_JST')
# 日本時間の前日の24時
yesterday = " since:"+ yesterday.strftime('%Y-%m-%d_00:00:00_JST')
# 検索クエリ。検索範囲を前日24時から当日24時までの24時間に設定
query = QUERY_WORDS + now + yesterday
これでクエリを API の入力にすれば、日本時間で1日分のツイートを取得できます。
注意する必要があるのは、API の結果に含まれるツイート時間(created_at)は UTC 表記になっていることです。結果も日本時間に合わせるなら変換が必要です。
Lambda からファイルを S3 に保存
Python と Twitter API を利用したツイート収集方法のファイルに保存する部分のコードを S3 に保存するように書き換えます。
コードの書き換えの他に Lambda の実行ロールに S3 のアクセスを許可するようにポリシーをアタッチします。
該当関数は以下になります。
import boto3
from io import StringIO
from datetime import datetime, timedelta, timezone
import pandas as pd
def putFileToS3(data,q):
until = datetime.now(JST)
since = until - timedelta(days=1)
file_name = '{0}_to_{1}.csv'.format(since.strftime('%Y-%m-%d'), until.strftime('%Y-%m-%d'))
# csvのカラム
columns = ["投稿日", "ID", "User_name", "Screen_name", "text", "favorite", "retweet_count", "followers", "follows", "user_mentions"]
df = pd.DataFrame(data)
df.columns = columns
csv_buffer = StringIO()
df.to_csv(csv_buffer)
content = csv_buffer.getvalue()
s3 = boto3.client('s3')
bucket = BUCKET_NAME
s3FilePath = QUERY_WORDS + "/{0}/{1}/{2}".format(until.year, until.month, file_name)
s3.put_object(Bucket=bucket, Key=s3FilePath, Body=content)
CloudWatch Events で定期実行
前述までのコードが想定通りに動けば、あとは毎日定時に Lambda が起動するように設定するだけです。これまでのものと組み合わせると最終的な構成は以下になります。
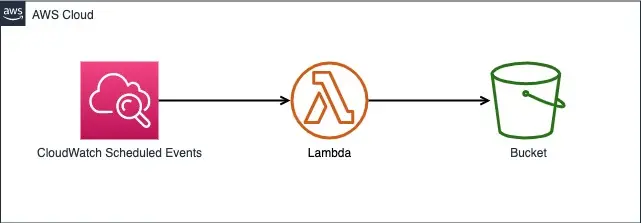
やり方は簡単で Lmabda のトリガーに CloudWatch Events を指定するだけです。
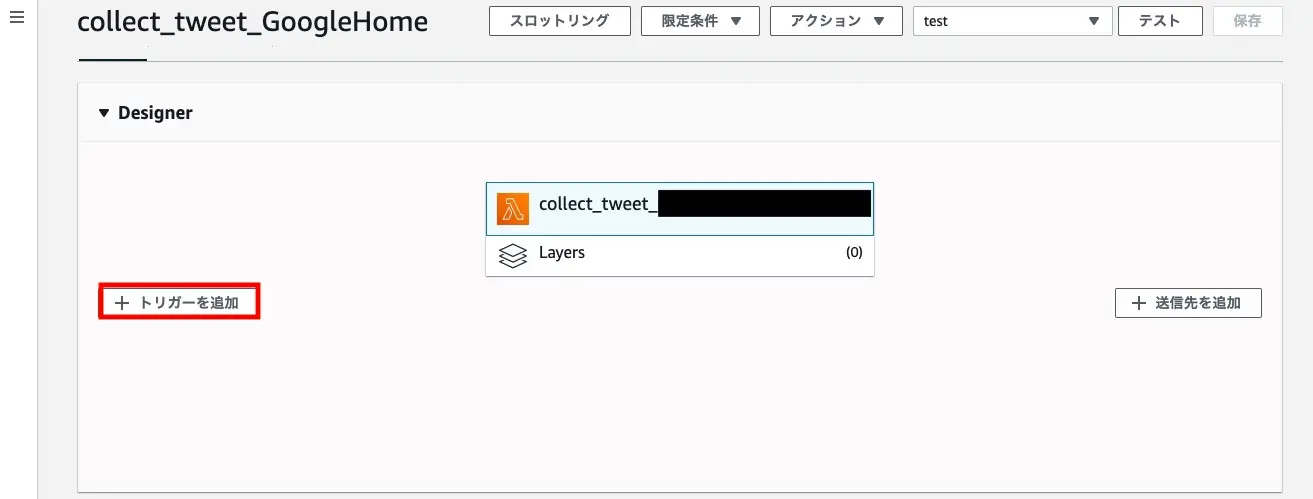
まずはブラウザから AWS のコンソールにアクセスし、Lambda 関数のページにアクセスします。アップロードがうまくいっていれば関数一覧に作成した関数があるはずです。
アップロードした関数を選択し、以下のようにトリガーの追加を選択します。
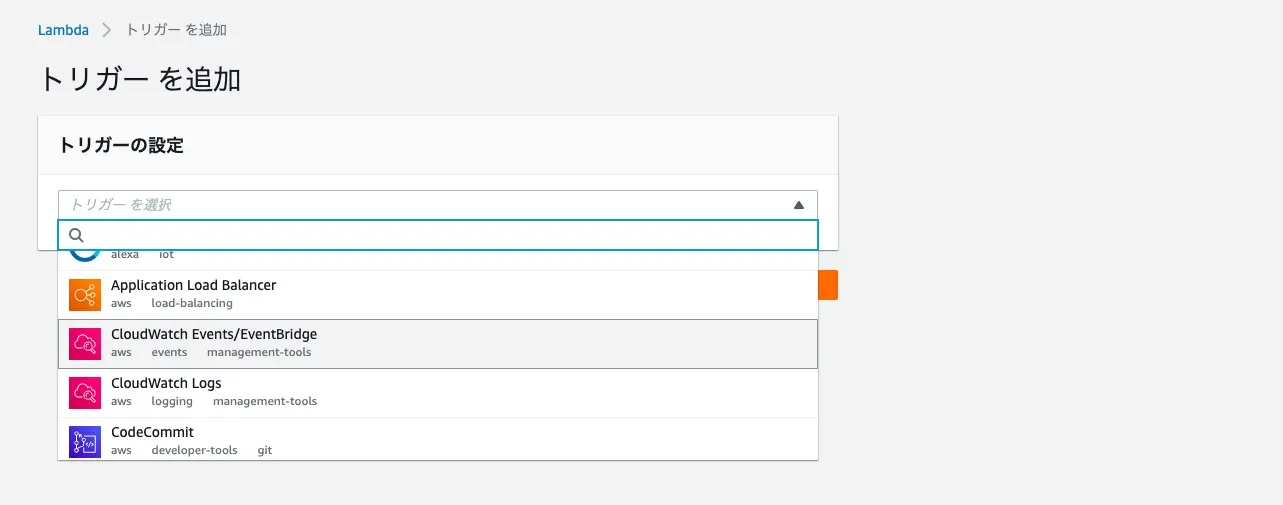
トリガーには CloudWatch Events を指定します。
次に CloudWatch Events の設定を行なっていきます。とはいってもイベントパターンをスケジュール式にして cron を書くだけです。
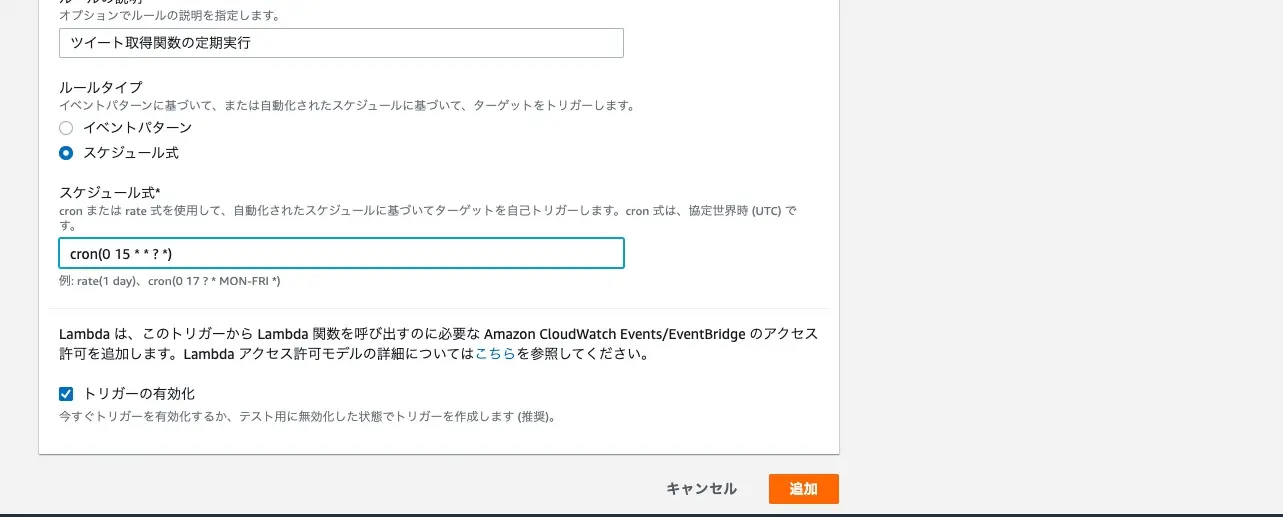
cron を書く際に気をつけるのはタイムゾーンが UTC になっていることです。日本時間で実行したいなら 9 時間ずらす必要があります。ちなみに画像のスケジュール式は毎日日本時間の 24 時に実行されるように書いてます。
cron でのスケジュール式の書き方は公式ページが参考になります。
まとめ
本記事では Docker で lambda-uploader を使う方法や AWS Lambda と CloudWatch Events を使ったツイート日時収集システムの構築方法についてまとめました。
詰まったところは AWS CLI の認証情報を Docker に渡す部分です。本当はスクリプトファイルを使わずにやりたかったのですが、力及ばずでした。。。
次は集めた情報を自然言語処理で前処理を行い簡単な可視化を行う記事を書こうと思ってます。