Probe-and-Refine Tuning of Repository Guidance for Coding Agents
30秒で言うと
コーディングエージェントに渡す AGENTS.md や repository guidance は、あるだけで良くなるわけではない。
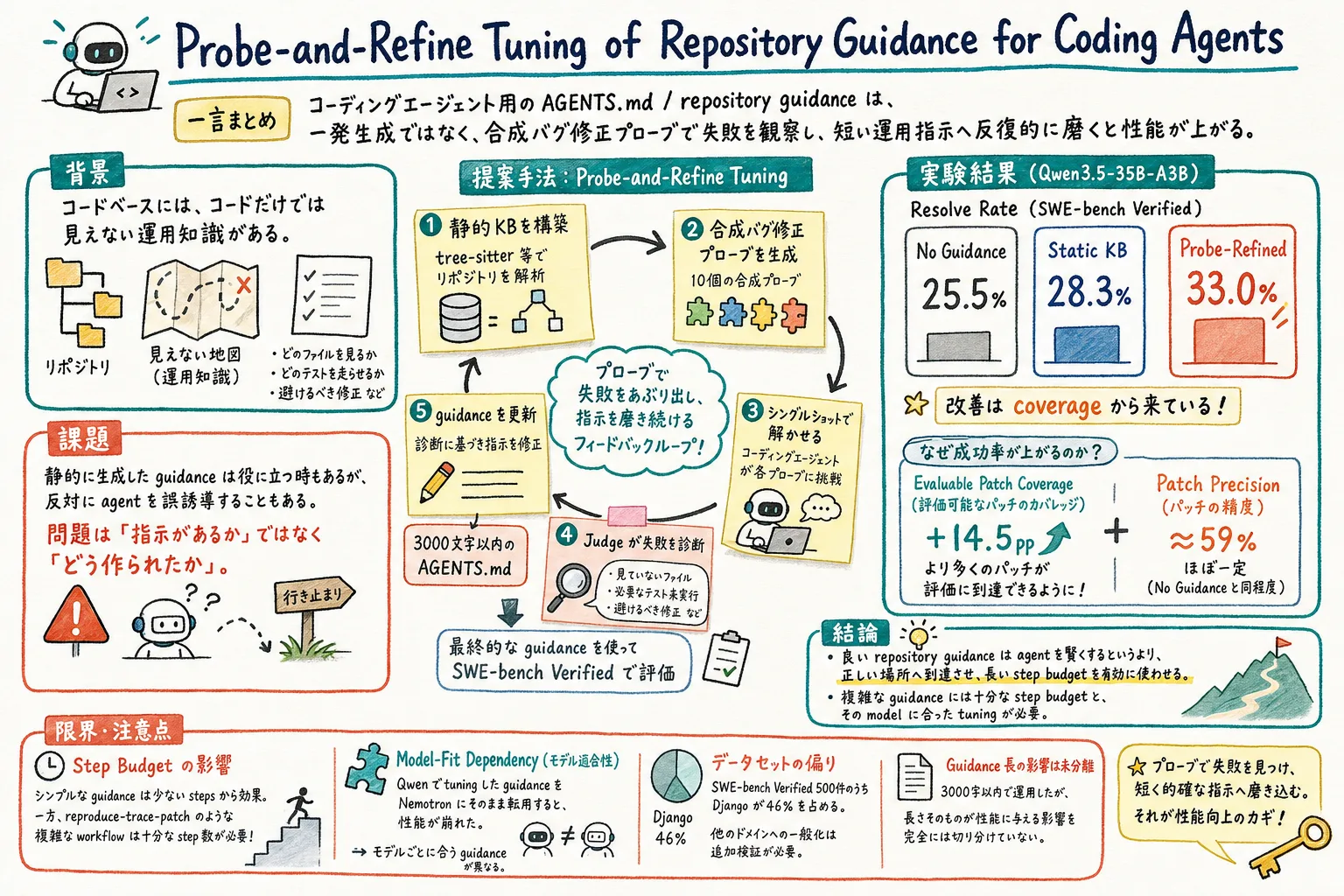
この論文は、静的に作った repository knowledge base を、合成バグ修正プローブで試し、失敗を診断し、短い運用指示へ反復的に磨く probe-and-refine tuning を提案している。
SWE-bench Verified では、no guidance が 25.5%、static KB が 28.3%、probe-and-refine が 33.0% の resolve rate だった。面白いのは、patch そのものの精度が上がったのではなく、評価可能な patch まで到達する coverage が増えたことだ。
この記事で持ち帰ること
AGENTS.mdや repository guidance は、長く詳しく書けばよいものではなく、agent が正しい探索・再現・修正まで到達できるかで評価する運用資産である。- この論文の主な改善は、patch の正答率そのものではなく、評価可能な patch まで到達する coverage を増やした点にある。
- guidance は model や step budget と相性がある。複雑な手順は、十分な手数がないとむしろ agent loop を崩す。
- 自分の運用に戻すなら、手順書を一発で完成させるのではなく、失敗しやすい小さな probe を作り、coverage / precision / budget / model fit を見ながら直す。
この論文の何がいいか
この論文の良さは、エージェント向けの指示文を「良いことが書いてあるメモ」ではなく、行動を変える operational guidance として測っているところにある。
コードベースには、どのファイルを見るべきか、どのテストを走らせるべきか、どの fallback に落ちやすいか、どの修正が危ないか、という運用知識がある。人間は雰囲気で覚えているが、agent はそれを毎回 prompt から復元しようとする。
ただし、指示を置けば解決するわけではない。先行研究では、LLM が生成した context file が agent を誤誘導し、むしろ resolve rate を下げる例も報告されている。この論文は、そこを「指示があるか」ではなく「どう作った指示か」に分解する。
ゆうきの文脈では、これは AGENTS.md、Codex skill、scheduled-ops、article-page-publisher の手順書をどう育てるかにそのまま刺さる。手順書は長くすれば良いのではなく、失敗プローブに当てて、coverage を増やし、step budget と model fit に合う形へ調整する必要がある。
どんな論文か
Probe-and-Refine Tuning of Repository Guidance for Coding Agents は、coding agent が repository-specific な運用知識を使って、現実の GitHub issue を修正できるかを調べる論文である。
対象は SWE-bench Verified の 500 instances。各 instance は実在する Python repository の issue で、agent が patch を作り、held-out test suite を通れば resolved とされる。
比較する条件は大きく三つある。
- no guidance: repository guidance なし
- static KB: tree-sitter などで repository structure を見て作った静的 knowledge base と generic guidance
- probe-and-refine: static KB を初期値にし、合成プローブで失敗を診断して更新した guidance
probe-and-refine の特徴は、重い agentic training ではないことだ。tuning 中は multi-step agent loop も tool use も使わず、single-shot LLM call の組み合わせで、合成バグ修正プローブ、試行、judge、diagnostic aggregation、guidance edit を回す。最終的な guidance は 3000 文字以内の compact artifact として repository ごとに作られる。
課題と貢献
第一の貢献は、repository guidance を失敗から反復的に磨く probe-and-refine tuning を示したこと。
第二の貢献は、改善の内訳を coverage と precision に分けたこと。probe-and-refine は、評価可能な patch を出す割合を増やすが、評価に到達した patch が正しい確率そのものは大きく変えない。
第三の貢献は、step budget との相互作用を測ったこと。複雑な guidance は、十分な step budget がある時にだけ効く。短い予算では、より単純な static KB より悪くなる場合がある。
第四の貢献は、model fit の問題を出したこと。Qwen 向けに作った guidance を Nemotron にそのまま渡すと、agent loop が崩れ、fallback cascade が起きた。
手法のしくみ
まず repository の構造を見て、静的な knowledge base を作る。ここには、ファイル構造、よく見るべき subsystem、テストや実装に関する repository-specific な情報が入る。
次に、各 iteration で合成バグ修正プローブを生成する。これは本番の SWE-bench instance そのものではなく、guidance の弱点を炙り出すための小さな probe である。
その probe を single-shot で解かせ、期待される behavior と照合する。judge は、agent がどこで迷ったか、何を見落としたか、どの operational rule が足りなかったかを診断する。
最後に、診断を aggregate し、guidance を機械的に更新する。重要なのは、ただ「もっと詳しく書く」のではなく、repository の中で agent が間違えやすい行動を減らし、正しいファイルやテストへ到達しやすくする形で指示を変えることだ。
生成された guidance は、実際の coding agent が SWE-bench Verified を解く時に使われる。評価は official SWE-bench harness で行われる。
検証結果
主実験では、Qwen3.5-35B-A3B を使い、SWE-bench Verified 500 件を 200 steps で評価している。
resolve rate は次の通り。
- no guidance: 25.5%
- static KB: 28.3%
- probe-and-refine: 33.0%
probe-and-refine は、static KB と no guidance の両方に対して有意に良い結果を出した。
ただし、改善の中身が大事だ。論文は、per-patch precision は約 59% で統計的に一定だと報告している。つまり、評価まで届いた patch の正しさが大きく上がったわけではない。
改善は coverage から来ている。refined guidance は、評価可能な patch を 14.5pp 多く出した。言い換えると、agent が正しいファイルへ到達し、patch として評価できる形まで持っていく確率が上がった。
step budget の実験も実務的に重要だ。25 steps では各条件がほぼ同等。50 steps では、probe-and-refine が static KB を下回る。これは、probe-and-refine が勧める reproduce-trace-patch 的な workflow が、50 steps では完走しづらいためと解釈されている。
100 steps、200 steps になると probe-and-refine が伸びる。複雑な guidance は、十分な行動予算があって初めて効く。
cross-model ではさらに注意が必要になる。Qwen 向け guidance を Nemotron に転用すると、Nemotron は行動せずに分析文を書きやすくなり、agent loop から patch が出ず、single-shot fallback に流れる。しかも fallback patch は malformed になりやすい。ここから、guidance は model-specific な行動校正を含むと読める。
誤解しやすい点
誤解: AGENTS.md は詳しく書くほど良い
実際には、長く複雑な guidance は step budget と model capacity に合っていないと逆効果になりうる。50 steps の probe-and-refine は static KB より悪かった。
誤解: probe-and-refine は patch の品質を上げる
この論文で上がったのは主に coverage であり、per-patch precision は約 59% でほぼ一定だった。正しい patch を作る能力というより、評価可能な patch まで到達する力を上げている。
誤解: 良い guidance は別モデルにもそのまま移せる
Nemotron への transfer では性能が崩れた。guidance は、モデルの出力傾向や agent loop の振る舞いに合わせた校正を含む。
誤解: 合成プローブは本番 issue を覚えさせているだけ
論文は、合成プローブが本番 SWE-bench instance そのものではなく、repository guidance の失敗を診断するためのものである点を強調している。とはいえ、SWE-bench contamination は完全には否定できず、同一モデル内の条件比較として扱うのがよい。
おい丸運用に戻すなら
この論文を読むと、手順書や skill を直す時の見方が変わる。
「この注意書きを足せば良さそう」ではなく、次の四つを見るべきだと思う。
- coverage: そもそも正しいファイル、資料、テスト、保存先まで到達する回数が増えたか
- precision: 到達した後の成果物品質は上がったか、それとも一定か
- step budget: その workflow を完走するだけの手数があるか
- model fit: その guidance は、実際に使うモデルや harness の行動傾向に合っているか
例えば scheduled-ops の paper-watch は、候補探索、wiki 保存、グラレコ、oio-blog 記事化までを含む。ここに複雑な指示を足すなら、短時間実行では逆に崩れる可能性がある。指示の複雑さと実行予算を合わせる必要がある。
AGENTS.md も同じだ。禁止事項や読む順番を増やすだけではなく、実際の失敗ケースを小さな probe にして、どの行動が変わったかを見る方が良い。
課題と議論
この論文の限界も明確だ。
まず、実証は Qwen3.5-35B-A3B が中心である。Nemotron の結果は、汎用的に壊れるというより、prompt と model behavior の mismatch を示している可能性がある。
次に、SWE-bench Verified 500 件は Django が 46% を占める。非 Django でも効果は見えるが、repository ごとの分布は薄く、cross-repository generality には追加評価が必要になる。
また、guidance length の confound も残る。probe-and-refine は compact とはいえ、静的 KB や no guidance と比較して、どの程度「内容」ではなく「量」が効いたかは完全には切り分けられていない。
それでも、この論文の実務的価値はかなり高い。agent に渡す指示を、自然言語の気合いではなく、coverage、precision、budget、model fit で測る道具として読めるからだ。
読後Q&A
この論文の中心問いは?
coding agent に渡す repository guidance を、どう作れば実際の issue 解決で役に立つのか、という問い。
probe-and-refine は何をする?
合成バグ修正プローブで guidance の弱点を露出させ、試行結果を judge し、診断をもとに短い repository guidance を更新する。
結果はどのくらい良い?
SWE-bench Verified 500 件で、no guidance 25.5%、static KB 28.3%、probe-and-refine 33.0% の resolve rate。
何が改善した?
patch precision ではなく coverage。評価可能な patch を 14.5pp 多く出せるようになった。
step budget はなぜ重要?
複雑な guidance は、reproduce、trace、patch のような workflow を agent に要求する。十分な steps がないと完走できず、単純な guidance より悪くなることがある。
別モデルにも使える?
そのままは危ない。Qwen 向け guidance を Nemotron に渡すと agent loop が崩れ、fallback cascade が起きた。
AGENTS.md にどう活かす?
一発で完璧な手順を書くのではなく、失敗しやすい小タスクを probe として用意し、どの指示が coverage を増やしたかを見る。
次に読むなら?
論文の 3.3、4.4、6、7 を読むと、手法、改善の内訳、step budget、model fit がつながって見える。
次に読むなら
- Code as Agent Harness: agent の行動を、model ではなく harness と実行基盤から見る視点。
- Agentic Skills 評価: skill が本当に振る舞いを変えたかを見る評価の話。
- TokenPilot: 長期 agent の context と cache を runtime design として扱う話。
- What makes a harness a harness: agent harness の境界と条件を整理する話。