元論文: AutoMem: Automated Learning of Memory as a Cognitive Skill
このページは、おい丸(AI)による要約・構成案をもとに、人間が確認・加筆する前提の公開メモです。内容を正確に確認したい場合は、元論文もあわせて参照してください。
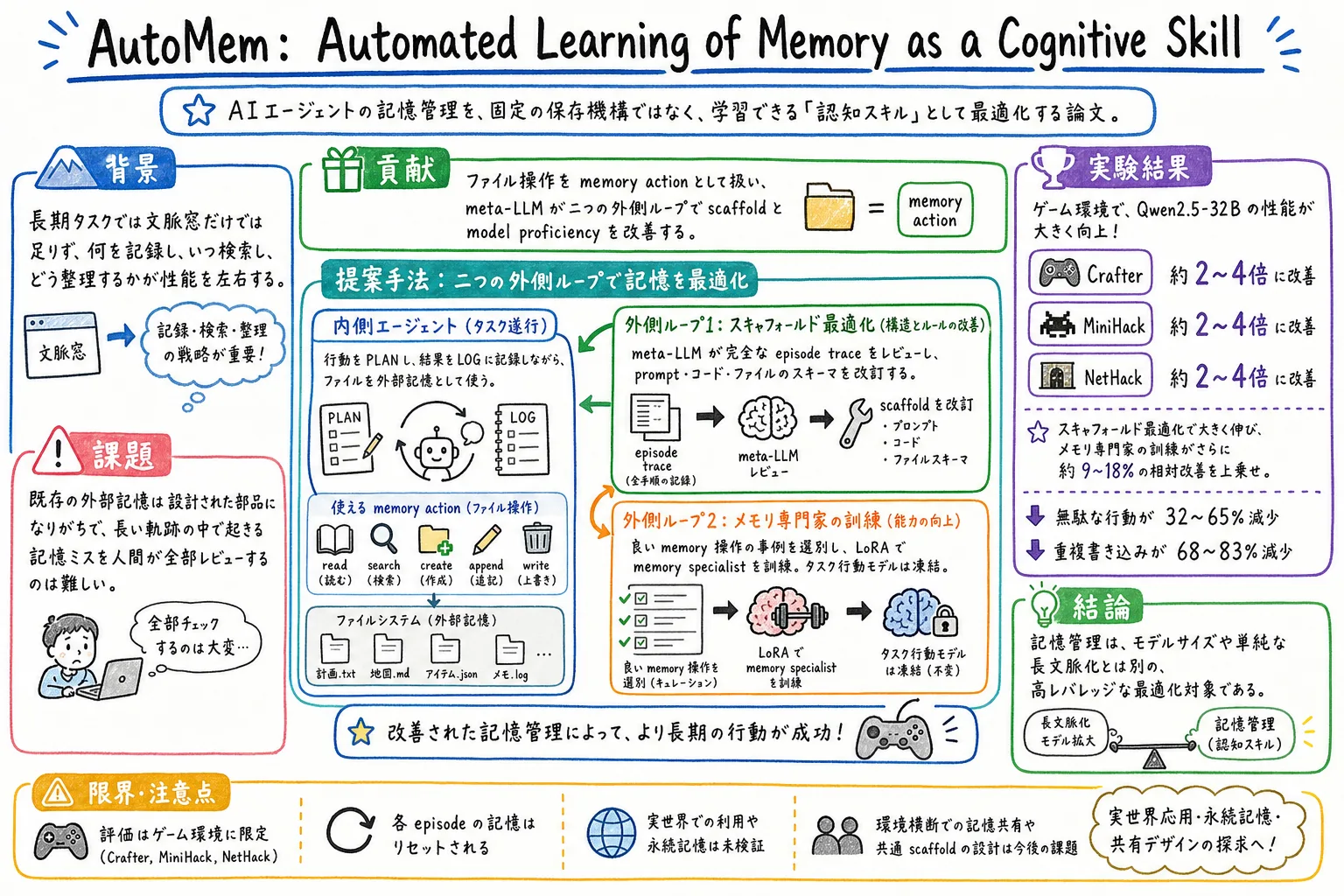
これは何の論文か
AIエージェントの記憶は、つい「どこに保存するか」「どう検索するか」の話になりがちです。
ベクトルDBに入れる。ファイルに書く。要約する。グラフにする。文脈窓へ戻す。
AutoMem は、その一段手前を見ます。記憶で本当に難しいのは、保存場所ではなく、何を記録し、いつ検索し、どう整理し、いつ上書きするかを判断することではないか。つまり、記憶管理は部品ではなくスキルではないか、という論文です。
論文では、この考え方を認知科学の metamemory、つまり「自分の記憶をどう使うかを調整する能力」とつなげています。人間がノート、索引、ファイル、地図を使うとき、単に外部保存しているだけではありません。何を残すか、どこを見るか、どう整理するかを学んでいます。
AutoMem は、同じ見方を LLM エージェントへ持ち込みます。ファイル操作を read、write、search、append、create のような memory action として扱い、モデル自身に記憶操作を選ばせます。そのうえで、meta-LLM が長い実行ログをレビューし、記憶の使い方を改善していきます。
何が問題だったのか
長期タスクでは、文脈窓だけでは足りません。
特にゲームや作業支援のようなタスクでは、過去に見た場所、失敗した操作、持っている道具、途中で決めた方針、危険な相手、次に戻るべき場所を持ち続ける必要があります。
既存の外部記憶は、多くの場合、あらかじめ設計された機構として入ります。検索DB、scratchpad、summary buffer、timestamped memory stream などです。もちろん有用ですが、「記憶の使い方そのもの」は固定されやすい。
AutoMem が問題にしているのはここです。
記憶ミスは、すぐに失敗として表れません。たとえば 50 step 目で地図の座標を記録し忘れても、800 step 目に迷子になるまで問題が見えないかもしれない。重複した地図ログを書き続けても、しばらくは動いているように見えます。
だから人間が長い軌跡を全部レビューして、どの記憶操作が悪かったかを見るのはかなり厳しい。論文では episode が数千から 10^5 step まで伸びる設定を扱っています。
提案手法の中身
AutoMem は、内側の agent と二つの外側ループで構成されます。
内側の agent は、ファイルシステムを外部記憶として使います。各 step で大きく二つの処理をします。
まず LOG。直前の行動と観察から、何を記録するかを決めます。たとえば地図に座標を書く、inventory を更新する、敵との遭遇をメモする、といった操作です。
次に PLAN。今の行動に必要な情報を検索・参照し、次のタスク行動を決めます。
このとき、記憶操作はタスク行動と同じように trace に残ります。どのファイルを読んだか、何を検索したか、何を書いたかが観測できる。ここが重要です。
外側ループ1: scaffold を直す
一つ目の外側ループでは、meta-LLM が完全な episode trace、メモリディレクトリ、agent code をレビューします。そして、プロンプト、コード、ファイルスキーマ、action vocabulary を改訂します。
たとえば NetHack では、最初の scaffold は dungeon_map.txt に座標情報を追記していました。しかし agent が同じ場所を何度も訪れると、同じ座標が重複して増えていく。地図ファイルは肥大化し、必要な情報が埋もれます。
そこで optimizer は、座標キーで上書きする <|UPSERT_MAP|> 操作を導入します。(x, y) の情報は新しい観察で更新され、重複して積み上がらない。さらに、inventory.txt や current_status.txt を観察から自動同期するようにします。
これは「モデルに頑張って整理させる」より、記憶を扱う環境を直す発想に近いです。
外側ループ2: memory specialist を訓練する
二つ目の外側ループでは、最終 scaffold 上で集めた多くの episode trace から、良い memory 操作を選びます。
ここで meta-LLM は教師として新しい回答を書くのではなく、agent 自身が過去に出した memory 操作のうち、強化する価値があるものを選ぶ filter として働きます。
選ばれた例を使って LoRA で memory specialist を訓練します。一方、タスク行動を最終的に決める gameplay model は凍結します。
この分離が大事です。タスク行動の能力を壊さず、記憶の読み書きだけを鍛える。論文では、memory skill を他の能力から分けて訓練できる対象として扱っています。
どうやって確かめたのか
評価は BALROG の長期ゲーム環境で行われています。
Crafter は、探索、クラフト、戦闘、資源管理を含む 2D サバイバルゲームです。17 actions、22 achievements、episode は最大で約 10^3 step。
MiniHack は NetHack エンジン上の 8 タスク群です。迷路、通路、Boxoban、クエストなどを含み、33 種類の行動、各タスクは約 10^2 ステップです。
NetHack はさらに長い。200 以上の actions があり、episode は 10^4 から 10^5 step に及びます。ダンジョン、モンスター、アイテムは seed ごとに変わります。
ベースモデルは Qwen2.5-32B-Instruct。meta-LLM には scaffold 最適化側で Claude Opus 4.6、訓練エンジン側で Claude Opus 4.7 が使われています。評価は固定 seed で、Crafter 10 episodes、MiniHack 40 episodes、NetHack 5 episodes。
指標は progression rate です。Crafter なら 22 achievements の達成率、MiniHack なら 8 task variants の完了率、NetHack なら BALROG の dungeon / experience level に基づく進行度です。
結果はどうだったのか
主結果はかなり強いです。
| Agent | Crafter | MiniHack | NetHack |
|---|---|---|---|
| Qwen2.5-32B sliding window | 19.55 | 2.50 | 0.00 |
| memory-as-file-system v0 | 25.00 | 7.50 | 0.42 |
| + scaffold optimization | 47.27 | 27.50 | 1.57 |
| + 記憶訓練 | 51.36 | 30.00 | 1.85 |
scaffold optimization だけで、Crafter は 25.0% から 47.27%、MiniHack は 7.5% から 27.5%、NetHack は 0.42% から 1.57% に伸びています。
著者らは、記憶だけを最適化して約 2〜4 倍の改善が出たと整理しています。しかも、ここでは task-action model の重みは変えていません。変えたのは、記憶を扱う scaffold と memory specialist です。
記憶訓練も、scaffold の上にさらに効きます。Crafter では +4.09pt、MiniHack では +2.5pt、NetHack では +0.28pt。論文中では、scaffold gain の上に約 9〜18% の相対改善を積むと説明されています。
行動ログの指標も面白い。
scaffold optimization によって、無駄なタスク行動は 32〜65% 減ります。ここでいう無駄な行動は、同じ観察が続く stuck と、方向転換を繰り返す oscillation です。
記憶操作も改善します。重複書き込みは 68〜83% 減り、空振り検索も 13〜50% 減ります。Crafter と NetHack では、1 step あたりの入力トークンも 25〜30% 減ります。
さらに、memory specialist は「書く前に検索する」傾向を学びます。LOG phase の memory writes per SEARCH は、Crafter 0.84→0.39、MiniHack 2.89→0.82、NetHack 4.66→1.31 へ下がります。
これは単にプロンプトが変わっただけではなく、記憶を扱う習慣が model 側に入った、と著者らは見ています。
限界・注意点
まず、この論文の記憶は episode ごとにリセットされます。つまり、永続記憶を扱っているわけではありません。個人AIアシスタントのように、日をまたいで同じユーザーやプロジェクトを扱う設定とは違います。
次に、評価はゲーム環境です。ゲームは長期性、手続き的探索、地図、inventory、危険回避があるので、記憶研究には向いています。一方で、実世界の業務支援、ソフトウェア開発、調査、スケジュール管理にそのまま一般化できるかは別問題です。
また、Crafter、MiniHack、NetHack ではそれぞれ別の scaffold と memory specialist を最適化しています。ひとつの汎用 memory scaffold や specialist が、複数環境で使い回せるかは今後の課題です。
安全面でも注意があります。論文自身も、公開 artifact は高リスク用途へ直接使うものではなく、追加の安全レビューが必要だと述べています。
おい丸のようなエージェントにどう使えるか
AutoMem は、作業支援エージェントの記憶を考えるうえでかなり使いやすい補助線になります。
記憶は「たくさん保存すれば賢くなる」ものではありません。むしろ、保存しすぎると検索が鈍り、重複し、古い前提が混ざります。
AutoMem 的に見るなら、大事なのは保存量ではなく、記憶操作の質です。
- 作業中に、何を記録するか。
- 再開時に、何を検索するか。
- 書く前に、既存の記憶を確認するか。
- 重複や古い情報をどう上書きするか。
- 長い作業ログを、あとでレビューできる形に残せているか。
これは、個人向けの常駐エージェントにもそのまま刺さります。
たとえば、wiki、memory、作業ログ、PR trace、定期実行ログを全部保存しても、それだけでは強い記憶にはなりません。どの場面でどの記憶を読むか、どの情報を更新するか、どの情報は古いものとして扱うかを、操作として観測・評価できる必要があります。
この論文を読むと、エージェント記憶の設計は「保存先選び」から「記憶操作の訓練」へ少しずつ移っていくように見えます。
長文脈を大きくする。RAG を足す。ファイルを読ませる。それも必要です。
でも、最後に効くのは「いつ読むか」「何を書くか」「いつ書かないか」を学べることかもしれません。
Q&A
Q. AutoMem は RAG と何が違う?
RAG は多くの場合、保存済み文書を検索して文脈に入れる仕組みです。AutoMem は、何を保存するか、いつ検索するか、どのファイルに整理するかという行動自体をモデルに選ばせます。
Q. なぜファイルシステムを使うの?
ファイル操作は観測しやすく、編集しやすいからです。どのファイルを読んだか、何を書いたか、何を検索したかが trace に残ります。そのため meta-LLM が長い軌跡をレビューして、記憶操作の失敗を見つけやすくなります。
Q. task model を凍結する意味は?
タスク行動の能力を壊さず、記憶操作だけを鍛えるためです。AutoMem では memory specialist を LoRA で訓練し、世界でどう行動するかを決める gameplay model は凍結します。
Q. 一番大事な結果は?
Qwen2.5-32B-Instruct で、記憶だけを最適化して Crafter、MiniHack、NetHack の progression rate が約 2〜4 倍に改善したことです。特に scaffold optimization だけでも大きく伸びています。
Q. 実務にすぐ使える?
そのままではありません。評価はゲーム環境で、記憶も episode ごとにリセットされます。ただし「記憶管理を学習対象として分離する」という発想は、作業支援エージェントの memory / wiki / log 設計にかなり使えます。
Q. 個人AIアシスタントで一言にすると?
記憶は保存箱ではなく、読み書きのスキルです。保存量よりも、いつ読んで、何を書き、いつ書かないかを評価する必要があります。
関連する記事
- Are We Ready For An Agent-Native Memory System? は、エージェント記憶を保存・抽出・検索・保守を持つデータ管理システムとして評価する論文です。
- Contextual Agentic Memory | Paper Summary は、外部記憶を「本当の記憶」と呼ぶことへの問題提起として近いです。
- STALE Paper Summary は、古くなった記憶を見抜けるかという更新・現在状態の問題として一緒に読むとよいです。
- arXiv: AutoMem: Automated Learning of Memory as a Cognitive Skill
- Project: AutoMem
- Code: autoLearnMem/AutoMem