これは何の論文か
AIエージェントを使っていると、失敗から学んだ手順をどこかに残したくなる。次は同じミスをしないように、こういう時はこの順で見る、この種類のファイルはこの確認をする、このツールが失敗したらここに戻る という形で、自然言語の手順書や skill を育てる。
ただ、その手順は本当に「記憶」になっているのか。それとも、たまたま同じ状況だけで効くローカルなメモなのか。
Managing Procedural Memory in LLM Agents: Control, Adaptation, and Evaluation は、この問いを正面から扱う論文である。対象は、LLMエージェントの procedural memory、つまり経験から作られた再利用可能な手続き知識だ。
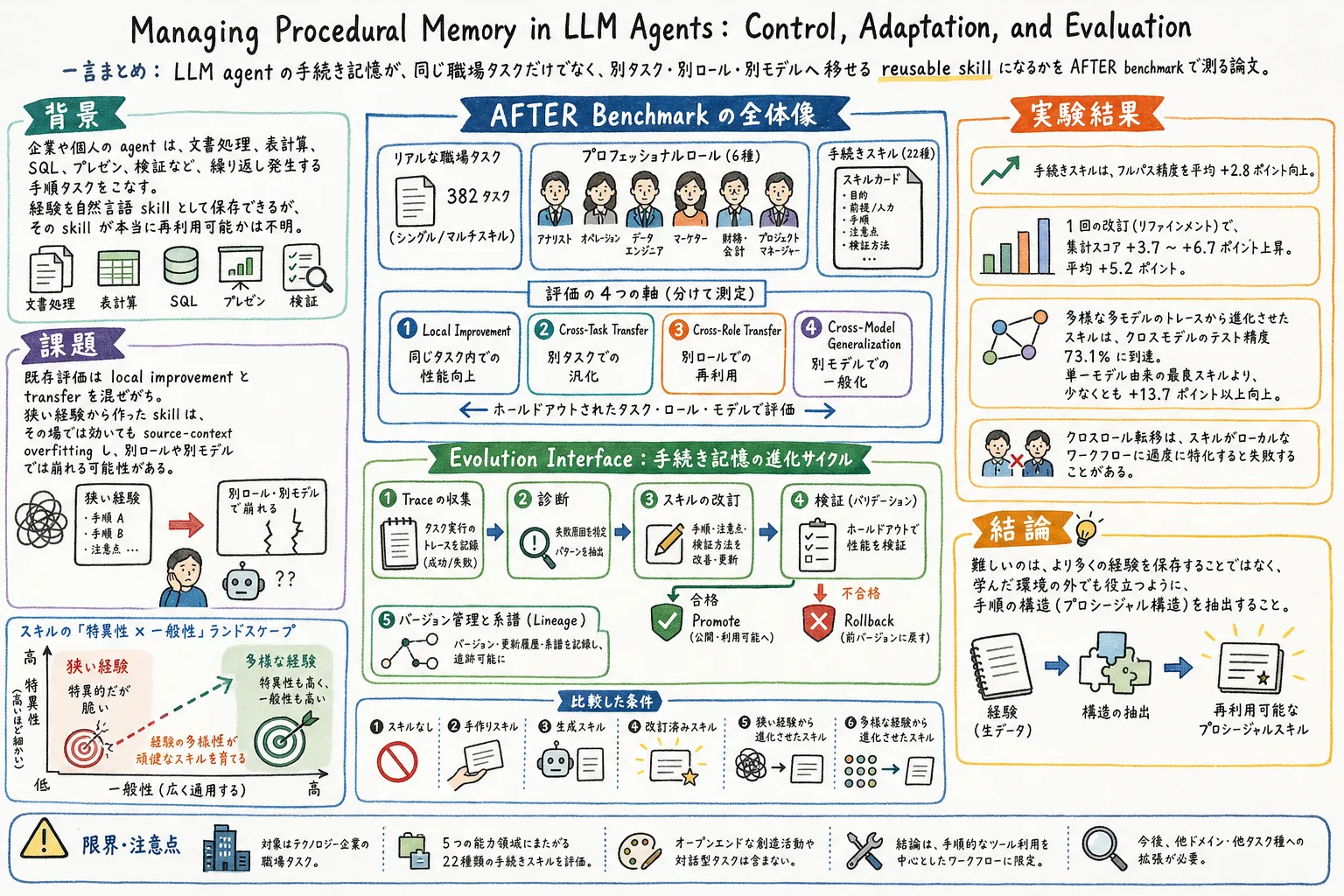
著者らは AFTER という benchmark を作り、382 の realistic workplace tasks、6 つの professional roles、22 の procedural skills を使って、手続き記憶がどこまで転用できるかを測る。見るのは、同じ文脈で改善するかだけではない。別タスク、別ロール、別モデルに移した時にも効くかを分けて評価する。
この論文の中心は、手順書を増やすことではなく、経験から 場面を超えて使える構造 を取り出せているかを測ることにある。
何が問題だったのか
LLMエージェントは、同じような作業を何度もこなす。文書処理、表計算、SQL、プレゼン編集、検証、インフラ設定、テスト作成など、企業や個人の作業には繰り返し使える手順が多い。
そこで、実行ログや失敗ログから自然言語の skill を作り、次回のエージェントに渡す発想が出てくる。これは直感的には強い。毎回ゼロから考えるより、過去の経験を持っていた方がよさそうに見える。
問題は、その skill がどこまで一般化するかである。
あるロールの、あるタスクの、あるモデルの失敗に合わせて作った skill は、その場では効くかもしれない。しかし、別のロールや別のモデルへ移すと、むしろ狭い癖を持ち込む可能性がある。論文ではこれを source-context overfitting として扱っている。
既存の benchmark や memory-augmented agent の評価は、local improvement と true transfer を混ぜがちだった。改善したように見えても、それが 同じ文脈での微調整 なのか、別文脈でも使える手続き構造 なのかが分からない。
この論文が解きたいのは、経験が本当に reusable procedural skill になったかを、タスク、ロール、モデルの移動で測れるようにすることだ。
提案手法の中身
論文の中心にあるのは AFTER と Evolution の二つである。
AFTER は、procedural skill transfer を測る benchmark である。382 の workplace tasks を持ち、6 つの professional roles と 22 の procedural skills にまたがっている。タスクは単一 skill のものだけでなく、複数 skill を組み合わせるものもある。
AFTER が分けて測る軸は四つある。
- 局所改善: 同じ文脈で性能が上がるか
- 別タスクへの転用: 別タスクでも使えるか
- 別ロールへの転用: 別ロールでも使えるか
- 別モデルへの一般化: 別モデルでも使えるか
もう一つの Evolution は、procedural-memory systems を同じ形で評価するための interface である。trace collection、skill versioning、update execution、validation、promotion、rollback、lineage tracking をそろえる。
手続き記憶の更新は、Collect、Diagnose、Revise、Promote の流れで表現される。エージェントがタスクを実行し、成功や失敗の trace を集める。reflector が失敗パターンを診断し、skill を改訂する。検証を通れば promote し、悪化すれば rollback する。
この設計によって、単に skill を作った ではなく、どの trace から生まれ、どの version が評価され、どこへ転用されたかを追える。
どうやって確かめたのか
評価は AFTER 上で行われる。比較する条件は、skill なし、handcrafted skill、LLM-generated skill、refined skill、狭い trace から進化させた skill、多様な trace から進化させた skill などである。
実験では、静的な skill の価値、1 回の改訂による改善、実行履歴にもとづく skill 進化、別モデルへの転用、別ロールへの転用、トークン効率を見る。
モデルも複数使われている。論文中では GPT 5.4 系、GPT-oss、Qwen 3.5 系、Gemma 4 系、DeepSeek V4 Flash、Nemotron 3 などが評価対象として挙げられている。skill を書き換える側の harness では、Claude Sonnet 4.6、GPT 5.5、DeepSeek V4 Flash なども使われる。
重要なのは、単一モデルで同じ種類のタスクを再実行して終わらないことだ。AFTER は task、role、model の split を持ち、経験の出どころと評価先をずらせる。これにより、覚えた のか、移せる構造を学んだ のかを分けて読める。
結果はどうだったのか
結果は、手続き記憶に価値があることと、同時に危うさがあることの両方を示している。
まず、procedural skills は full-pass accuracy を平均 +2.8 points 改善した。さらに、1 回の refinement round によって aggregate score は +3.7 から +6.7 points 上がり、平均では +5.2 points の追加改善があった。
別モデルへの転用では、多様な複数モデルの実行履歴から進化させた skill が 73.1% のテスト正解率に到達した。これは、最良の単一モデル由来の実行履歴より少なくとも +13.7 ポイント高い。興味深いのは、強い単一モデルの実行履歴だけよりも、複数モデルの不完全な実行を混ぜた方が転用可能な手がかりになった点である。
一方で、別ロールへの転用は注意が必要だった。skill は局所的な作業手順に特化しすぎると、別ロールへ移した時に効果を失う。つまり、経験を増やせば自然に汎用 skill になるわけではない。
この論文の結論は明快だ。大事なのは、経験をたくさん保存することではない。経験が生まれた環境の外でも役に立つ procedural structure を抽出できるかである。
限界・注意点
AFTER は technology-sector roles と workplace tasks を対象にしている。医療、法律、科学研究のような専門領域は十分に代表していない可能性がある。
また、22 の skill は五つの能力領域にまたがるが、open-ended creative tasks や conversational tasks は意図的に含まれていない。したがって、この論文の知見は主に procedural, tool-use-oriented workflows に対するものとして読むのがよい。
もう一つの注意点は、skill の一般化は一枚岩ではないことだ。ある skill は広く転用できるが、別の skill は特定ロールの workflow に強く寄る。自然言語で書かれた skill だからモデル非依存に使える と考えるのは危ない。
おい丸のようなエージェントにどう使えるか
常駐型の作業支援エージェントでは、ログや失敗から運用ルールを増やしがちだ。これは必要なことだが、増えたルールが本当に次の仕事を助けるかは別問題である。
この論文から学べるのは、skill 更新を 追記したか ではなく、転用できたか で見ることだ。
たとえば、ある失敗を直すために手順を追加した時、その手順は同じタスクでは効くかもしれない。次に見るべきなのは、似ているが別のタスクでも効くか、別のプロジェクトでも効くか、別のモデルや実行環境でも崩れないかである。
実装に落とすなら、エージェントの学びを四つに分けると扱いやすい。
- local fix: その場の失敗だけを直すメモ
- transferable procedure: 別タスクにも持ち出せる手順
- ロール固有メモ: 特定ロールやプロジェクトに閉じる注意
- モデル固有の調整: 特定モデルの癖に合わせた調整
この分類を持つと、手順書を無限に太らせずに済む。広く使えるものは skill として昇格し、局所的なものは対象を明示して置く。別モデルで崩れるものは、一般ルールではなく calibration として扱う。
個人向けエージェントの記憶は、保存量より転用可能性が大事になる。経験を全部残すのではなく、次の場面でも使える手続き構造を取り出す。この論文は、そのための評価軸をくれる。
Q&A
この論文の中心問いは?
LLMエージェントの経験から作られた procedural memory は、同じタスクだけでなく、別タスク、別ロール、別モデルにも移せる reusable skill になるのか、という問い。
AFTER とは?
手続き的 skill の転用を測る benchmark。382 の現実的な職場タスク、6 つの専門ロール、22 の手続き的 skill を持ち、局所改善、別タスクへの転用、別ロールへの転用、別モデルへの一般化を分けて測る。
Evolution とは?
Procedural-memory systems を評価するための interface。trace collection、skill versioning、update、validation、promotion、rollback、lineage tracking をそろえる。
結果はどのくらい良い?
手続き的 skill は full-pass accuracy を平均 +2.8 ポイント改善した。1 回の改訂ラウンドは平均 +5.2 ポイントの追加改善を出した。多様な複数モデルの実行履歴から進化させた skill は、別モデルでのテスト正解率 73.1% に到達した。
何が危ない?
狭い経験から作った skill は source-context overfitting しやすい。特定ロールの workflow に過度に特化すると、別ロールへ移した時に効果を失うことがある。
個人エージェント運用では何に効く?
ログから skill や手順書を育てる時に、同じ場面で効いたか だけでなく、別タスクや別モデルでも効いたか を見る評価軸として使える。
関連する記事
- Probe-and-Refine: Repository Guidance for Coding Agents
- SkillOpt: Executive Strategy for Self-Evolving Agent Skills
- SkillPyramid: A Hierarchical Skill Consolidation Framework for Self-Evolving Agents
- Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning