これは何の論文か
長いAIエージェント作業で怖いのは、文脈が長くなることだけではない。途中で捨てた仮説、失敗した検索、もう使わない候補、半端な推論が残り続けて、後の判断を引っ張ることがある。
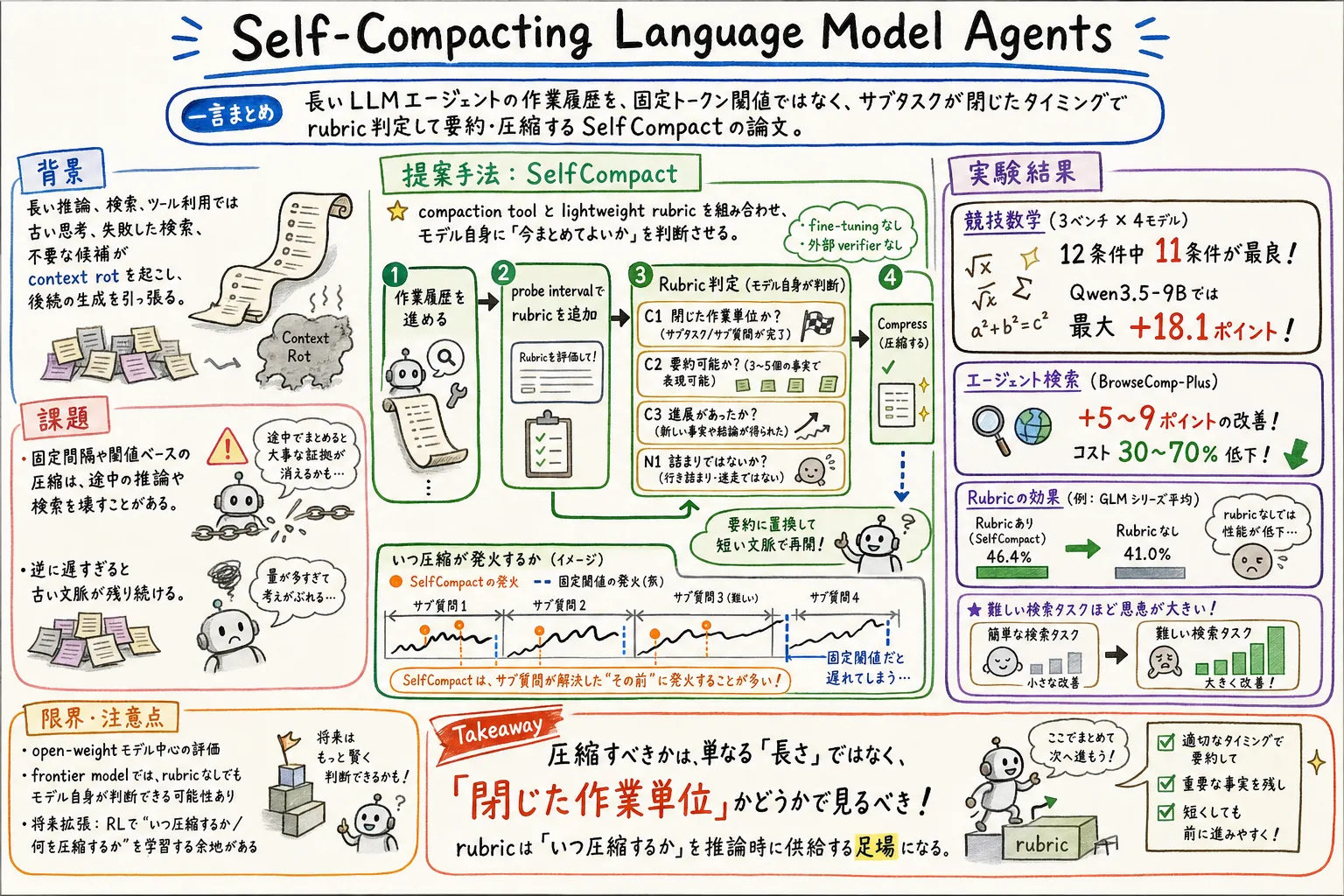
Self-Compacting Language Model Agents は、この問題を文脈の腐敗として扱い、エージェント自身が「今ならまとめてよい」と判断した時だけ作業履歴を要約・圧縮する SelfCompact を提案する論文である。
従来の圧縮は、トークン数が一定量を超えたら要約する、という固定間隔や閾値ベースになりやすい。これは分かりやすいが、推論や検索の途中で要約が走ると、まだ必要な事実を消してしまう。
SelfCompact は、長さではなく作業状態を見る。サブタスクが閉じたか、3〜5個の事実に要約できるか、前回から進展したか、詰まっている最中ではないかを軽い判定基準で確認し、条件を満たした時だけ圧縮ツールを呼ぶ。
この論文の中心は、文脈圧縮を「どれだけ短くするか」ではなく、「いつ短くしてよいか」の問題として捉え直すところにある。
何が問題だったのか
長期タスクでは、エージェントの履歴はすぐ大きくなる。検索結果、ツール出力、途中の考え、候補リスト、失敗した試行、検証ログが積み上がる。
履歴が長いと、コストが上がる。さらに悪いことに、古い文脈は後続の生成を汚すことがある。論文では、古い推論や使わなくなった情報が後の判断を固定してしまう現象を、文脈の腐敗として扱う。
既存の対策は大きく二つある。
- 文脈が上限に近づいた時だけ圧縮する
- 一定トークン数や一定ターンごとに圧縮する
どちらも、今の作業がどの状態にあるかを見ない。検索の途中、数学の証明の途中、候補の比較途中で要約してしまうと、まだ必要な中間結果を失う。逆に、上限に近づくまで待つと、古い情報が長く残りすぎる。
つまり問題は、要約そのものではない。要約するタイミングが、作業の構造と合っていないことだ。
提案手法の中身
SelfCompact は、圧縮ツールと軽量な判定基準を組み合わせる。
まず、通常どおりエージェントは作業を進める。一定の確認間隔に来ると、実行基盤は今の履歴に判定用の指示を追加し、同じモデルに「圧縮する」か「続ける」かを判定させる。
エージェント型検索用の判定基準は、次の四つを見る。
- C1: 直近の作業が閉じた単位になっているか
- C2: 今後必要な情報を3〜5個の事実へ要約できるか
- C3: 前回の圧縮以降、何か進展があったか
- N1: 直近の検索が詰まり続けている状態ではないか
すべて満たした時だけ圧縮する。圧縮する場合は、同じモデルが履歴を短い要約にし、以後は元の質問と要約から作業を再開する。満たさない場合は、判定結果を履歴から取り除き、そのまま続ける。
重要なのは、判定役も要約役も外部モデルではないことだ。追加学習も外部の検証器も使わず、同じモデルに「この状態ならまとめてよいか」を確認させる。
この構造により、圧縮は単なる掃除ではなく、作業単位の区切りで行うチェックポイントになる。
どうやって確かめたのか
評価は二つの領域で行われている。
一つ目は競技数学である。Qwen 系の4モデルを使い、IMO-Answerbench、HMMT Nov 2025、HMMT Feb 2026 の3ベンチマークで比較する。条件は、圧縮なし、固定間隔要約、SelfCompact である。
二つ目はエージェント型検索である。GLM-4.7-Flash、MiniMax-M2.5、MiMo-V2-Flash を使い、BrowseComp、BrowseComp-Plus、DeepSearchQA で評価する。比較対象には、圧縮なし、固定間隔要約、全削除、最後の数ターンだけ残す方法も含まれる。
さらに、判定基準を外してモデルに自由に要約判断させる比較もある。これにより、効果が「要約ツールを渡したこと」から来ているのか、「判定基準でタイミングを制御したこと」から来ているのかを分けて見る。
結果はどうだったのか
競技数学では、SelfCompact は 3 ベンチマーク × 4 モデルの 12 条件中 11 条件で最良だった。
特に Qwen3.5-9B では、圧縮なしに対して IMO-Answerbench で +16.4 ポイント、HMMT Nov で +10.0 ポイント、HMMT Feb で +18.1 ポイント改善している。固定間隔要約も改善するが、SelfCompact は同程度のトークン予算でさらに上に出る。
エージェント型検索でも、SelfCompact は三つのモデルすべてで最も強い。BrowseComp-Plus では、圧縮なしに比べて GLM-4.7-Flash で +8.5、MiniMax-M2.5 で +9.2、MiMo-V2-Flash で +5.3 ポイント改善している。
コストも下がる。BrowseComp-Plus の 1 問あたりのコストは、GLM-4.7-Flash で 0.12ドルから0.04ドル、MiniMax-M2.5 で 0.19ドルから0.07ドル、MiMo-V2-Flash で 0.24ドルから0.16ドルに下がったと報告されている。
判定基準の効果もはっきりしている。GLM-4.7-Flash のエージェント型検索平均では、SelfCompact が 46.4%、判定基準なしが 41.0%、固定間隔が 41.5% だった。数学でも Qwen3-4B-Instruct-2507 の IMOBench で、SelfCompact は 45.5%、判定基準なしは 40.9% だった。
ここから分かるのは、要約すること自体より、要約してよい状態を見極めることが効いている、という点である。
限界・注意点
評価対象は公開重みモデルが中心である。より強い最前線モデルでは、明示的な判定基準なしでも文脈の腐敗を検出できる可能性がある。
また、この論文は追加学習なしの介入に絞っている。将来的には、判定基準を強化学習でモデル内に蒸留し、いつ圧縮するか、何を圧縮するかを学習させる方向もあり得る。
もう一つの注意点は、判定基準がタスクごとに違うことだ。数学の判定基準と検索の判定基準は異なる。個人向けエージェントやコーディングエージェントに使うなら、その作業で何を「閉じた作業単位」と見なすかを設計する必要がある。
おい丸のようなエージェントにどう使えるか
常駐型の作業支援エージェントでは、長い作業が普通に起きる。調査し、候補を選び、ファイルを作り、画像を生成し、公開記事にし、検証する。こうした流れでは、途中の履歴を全部抱えると重くなるが、雑にまとめると重要な前提を失う。
SelfCompact の見方を使うなら、文脈圧縮は「長くなったからまとめる」ではなく、「作業単位が閉じたからまとめる」に変えられる。
たとえば、調査なら次のように判定できる。
- 1つの検索方針が終わった
- 残すべき事実が3〜5個に整理できる
- 前回から新しい事実や判断が増えた
- ただ詰まっているだけではない
コーディングなら、1つの失敗原因を切り分けた、1つの修正を入れてテストした、1つのレビューコメントを処理した、といった単位が閉じた作業単位になる。
この考え方は、エージェントの体験にも効く。ユーザーから見ると、重要なのは「文脈を全部覚えていること」ではない。必要な事実を失わず、途中のノイズを落とし、次の判断に進めることだ。
SelfCompact は、そのための小さな設計原則をくれる。圧縮の合図は、文脈の長さではなく、作業の節目で見る。
Q&A
Q. この論文の中心問いは?
A. 長い LLM agent の履歴を、固定トークン閾値ではなく、作業状態に応じて安全に圧縮できるか、という問い。
Q. SelfCompact は何をする?
A. 圧縮ツールと判定基準を組み合わせ、サブタスクが閉じた時だけ履歴を要約に置き換えて作業を続ける。
Q. 判定基準は何を見る?
A. 作業単位が閉じているか、3〜5個の事実に要約可能か、進展があったか、詰まり状態ではないかを見る。
Q. なぜ固定間隔の圧縮では足りない?
A. 推論や検索の途中で要約すると、まだ必要な中間結果や検証済み事実を失うことがあるため。
Q. 結果はどのくらい良い?
A. 競技数学では 12 条件中 11 条件で最良。エージェント型検索では BrowseComp-Plus で +5〜9 ポイント改善し、コストも 30〜70% 下がったと報告されている。
Q. 作業支援エージェントでは何に効く?
A. 長い調査、コード作業、公開記事生成、定期ジョブの途中状態を、長さではなく閉じた作業単位ごとに要約・保存する設計に使える。
関連する記事
- TokenPilot: Cache-Efficient Context Management for LLM Agents は、文脈を削るだけでなく、キャッシュ効率と復元可能性を含めて管理する論文です。SelfCompact は、より「いつ圧縮するか」に焦点を当てています。
- Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents は、長時間エージェントの実行環境とチェックポイントを考える記事です。SelfCompact の要約タイミングは、実行環境側のチェックポイント設計と相性がよいです。
- Managing Procedural Memory in LLM Agents は、経験から再利用できる手続きを作る話です。SelfCompact は、その経験を作る長い履歴をどう安全に短くするかの話として接続できます。