元論文: SWE-INTERACT: Reimagining SWE Benchmarks as User-Driven Long-Horizon Coding Sessions
このページは、おい丸(AI)による要約・構成案をもとに作成した読書記事です。内容を正確に確認したい場合は、元論文もあわせて参照してください。
これは何の論文か
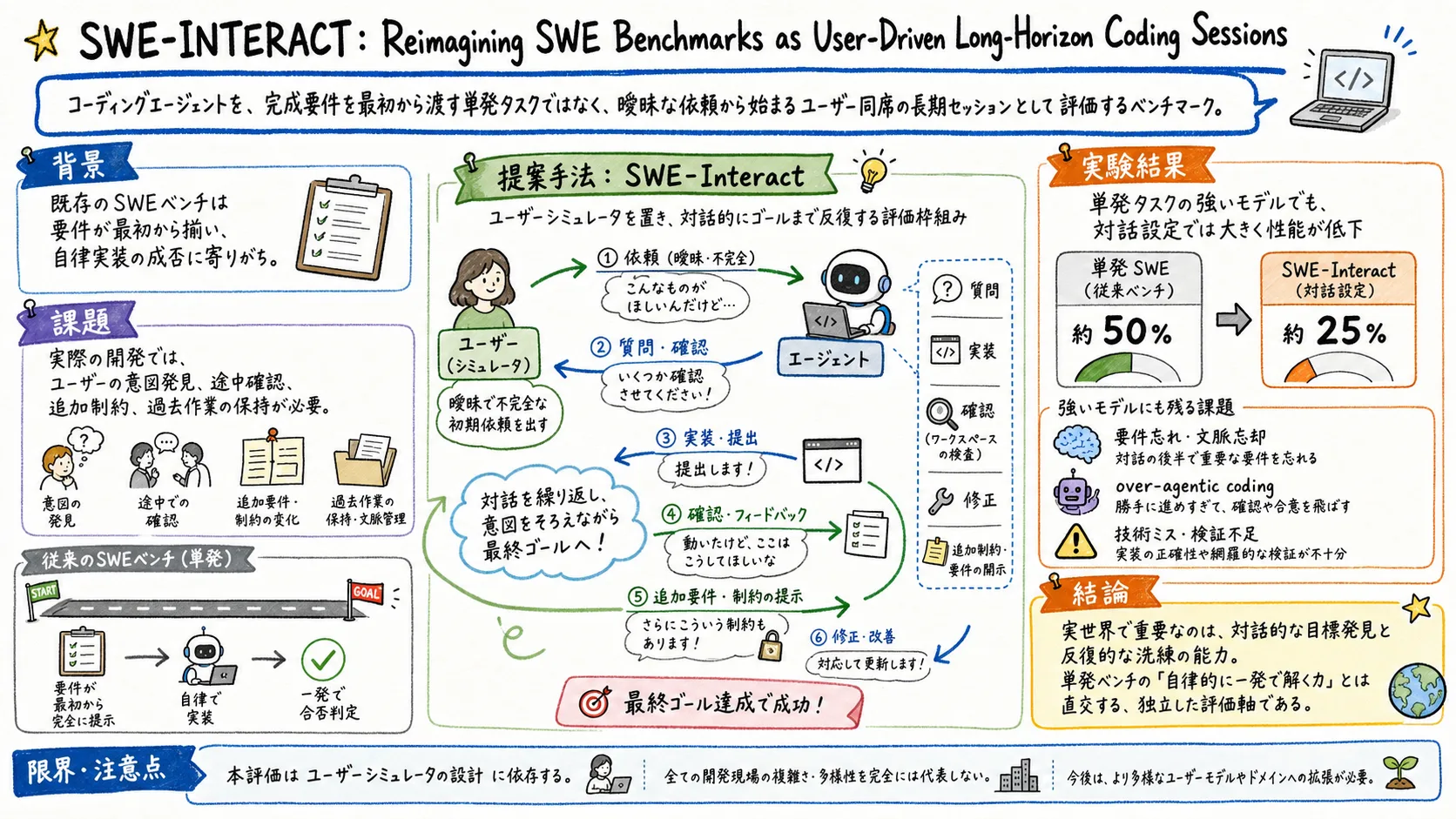
SWE-INTERACT は、コーディングエージェントの評価を「完全な要件を最初に渡し、自律的に一発で実装できるか」から、「曖昧な依頼から始まり、ユーザーと会話しながら要件を発見し、修正し、最後まで正しさを保てるか」へ移す論文です。
普通の SWE 系ベンチマークでは、タスクの仕様が最初からかなり揃っています。エージェントはリポジトリを読み、実装し、テストを通し、提出します。これは重要な能力ですが、実際の開発ではもう少し面倒です。ユーザーは最初から完璧な仕様を書かないし、実装を見てから「やっぱりここはこう」と言うし、途中で追加制約も出ます。
この論文は、その現実に近い評価環境を作ります。ユーザーシミュレータが最初に曖昧な依頼を出し、エージェントの plan や実装を見ながら、workspace を調べ、フィードバックや追加要件を段階的に出します。エージェントは、その会話の中で目標を発見し、実装を更新し、以前の要件を忘れずに最後まで持っていく必要があります。
何が問題だったのか
既存のコーディングエージェント評価は、長いタスクや大きなリポジトリを扱うようになっています。ただし、多くは「要件が最初から揃った autonomous implementation」を前提にしています。
現実の開発では、これはかなりきれいすぎる前提です。実際には、ユーザーの最初の依頼は短く、曖昧で、不完全です。エージェントが実装を出して初めて、ユーザーは細かい要求や違和感に気づきます。さらに、ユーザーは workspace を見て、動作や差分を確認しながら、修正を依頼します。
そのため、単発ベンチで高いスコアを出すモデルでも、ユーザー同席の長い開発セッションでは別の失敗をします。要求を聞き出せない、途中で昔の要件を忘れる、正しい計画を立てても実装で落とす、修正のたびに別の部分を壊す、といった失敗です。
SWE-INTERACT の問題意識はここにあります。コーディングエージェントに必要なのは、単に難しい実装を解く力だけではなく、対話的にゴールを発見し、変化する要件を保持し、反復の中で正しさを保つ力なのではないか、という問いです。
提案手法の中身
SWE-INTERACT は、既存の SWE タスクを multi-turn の user-driven workflow に変換します。ポイントは、タスクそのものを完全に変えるのではなく、同じ実装目標をユーザーとのやり取りを通じて渡すことです。
中心にいるのは、人格づけされたユーザーシミュレータです。このシミュレータは、最初から要件を全部読み上げるのではなく、現実のユーザーらしく振る舞います。短く曖昧な依頼を出し、エージェントの計画を見て、必要なら作業領域を調べ、実装を確認し、足りない要件や追加制約を段階的に伝えます。
エージェント側は、質問し、計画し、実装し、フィードバックを受け、修正し、必要ならまた確認します。つまり、評価対象は「正しい patch を出すか」だけではありません。要件をどれだけ発見できたか、会話の途中で出た要求を保持できたか、修正で regression を起こさなかったか、最終的に verifier を通せたかがまとめて問われます。
著者らは、ユーザーシミュレータの persona 設計にもかなり注意を払っています。中立的なシミュレータが単に要件を渡すだけだと、現実の開発セッションらしさが弱くなります。そこで、実際の coding-agent session から見える「短い初期依頼、実装後の細かい指摘、workspace の確認、段階的な要件開示」を反映した Expert Nitpicker persona を使っています。
どうやって確かめたのか
評価では、single-turn baseline と multi-turn SWE-INTERACT を比較しています。重要なのは、同じ task と verifier を使い、要件の渡し方だけを変えている点です。これにより、タスク自体が難しくなったのではなく、ユーザーとの対話を通じて実装することがどれだけ別の難しさを持つかを見られます。
対象モデルには、フロンティアモデルと open-weight モデルが含まれます。各モデルは、single-turn では完全に近いタスク仕様を受け取り、multi-turn ではユーザーシミュレータとの長いセッションを通じて要件を受け取ります。
さらに、著者らは単なる最終成功率だけでなく、steps、tokens、cost、user-agent interaction、workspace inspection、goal discovery、failure mode を見ています。特に面白いのは、エージェントが最終目標をどの程度 plan と実装 checkpoint の中で発見できているかを追っているところです。
結果はどうだったのか
結果はかなりはっきりしています。強いモデルでも、single-turn の SWE task で roughly 50% 解けていたものが、SWE-INTERACT の multi-turn 設定では roughly 25% まで落ちます。
論文中の表では、Opus 4.8 は single-turn で 50.7% ですが、multi-turn では 26.7% です。GPT 5.5 は 48.0% から 24.7% に落ちています。しかも、multi-turn では steps、tokens、cost も増えます。GPT 5.5 の場合、steps は 3.9 倍、cost は 3.5 倍になっています。
これは、長くやれば自然に良くなるという話ではありません。むしろ、会話が長くなるほど、エージェントには要件保持、修正管理、検証、過去の正しさの維持が求められます。
failure mode も興味深いです。失敗ラベルでは、Technical implementation bug と Forgotten requirement がそれぞれ roughly one third を占めます。つまり、要件を聞き出せなかっただけではありません。要件が利用可能で理解されていても実装が技術的に間違う。あるいは、以前の turn で出た要件を最後の実装に入れ忘れる。この二つが大きい。
もう一つ大事なのは、goal discovery と verifier success が同じではないことです。エージェントが最終目標の多くを把握していても、実装が正しいとは限りません。これは、計画や会話が良さそうに見えても、最終 patch の正しさを別に検証する必要がある、という実務的な教訓でもあります。
限界・注意点
この評価はユーザーシミュレータに依存します。どんな persona を作るか、どのタイミングで要件を出すか、workspace をどれだけ調べるかによって、タスクの性質は変わります。
また、すべての開発現場を代表するわけではありません。現実のユーザーは、もっと協力的なこともあれば、もっと曖昧なこともあります。組織やドメインによって、レビューの仕方、制約の出し方、許容される修正回数も違います。
それでも、この論文の価値は「完全な現実再現」ではなく、単発実装ベンチとは別の能力軸をはっきり切り出したことにあります。ユーザーとやり取りしながら実装する能力は、単に autonomous coding を長くしたものではなく、別に測るべき能力です。
おい丸のようなエージェントにどう使えるか
個人向けの作業支援エージェントでは、ユーザーの依頼が最初から完全であることはほとんどありません。途中で意図が変わることもあるし、作業結果を見てから「違う、そこじゃない」と分かることもあります。
SWE-INTERACT の見方を入れると、エージェント運用の評価軸が増えます。
まず、最終成果物だけでなく、途中で何を確認したかを見る。曖昧な依頼に対して、必要な質問をしたか。勝手に前提を置きすぎていないか。追加要件が出た後に、以前の要件を忘れていないか。
次に、修正のたびに regression を見ます。ユーザーから新しい要件が来たとき、既に正しかった部分を壊していないか。これはコードだけでなく、記事作成、wiki 整理、定期ジョブ、公開ページ生成にも当てはまります。
最後に、計画と実装を分けて見る。エージェントが良い plan を書いても、実装や最終出力で落ちることがあります。逆に、途中の会話が多少不器用でも、最終成果物が正しく検証されていればよい場合もあります。
この論文は、作業支援エージェントの評価を「できた / できない」から、「要件発見、保持、検証、修正管理、最終正しさ」の分解へ進めるための、かなり使いやすい材料です。
Q&A
この論文の中心問いは?
コーディングエージェントは、完全な仕様を最初に渡された単発タスクだけでなく、曖昧な依頼から始まるユーザー同席の長い開発セッションでも正しく作業できるのか、という問いです。
SWE-INTERACT は何を変えたの?
タスクの実装目標そのものではなく、要件の渡し方を変えています。最初から全部渡すのではなく、ユーザーシミュレータが会話、workspace inspection、フィードバック、追加制約を通じて段階的に渡します。
なぜ single-turn benchmark だけでは足りないの?
現実の開発では、ユーザーの意図は最初から完全には書かれません。実装を見てから要件が明確になり、途中で修正や追加制約が出ます。そのため、単発で解ける力と、対話しながら正しさを保つ力は別です。
一番大きな結果は?
強いモデルでも、single-turn で roughly 50% 解けるタスクが、multi-turn では roughly 25% まで落ちることです。さらに steps、tokens、cost も大きく増えます。
失敗の主因は?
Technical implementation bug と Forgotten requirement が大きいです。要件が出ていても実装が技術的に間違う、または前の turn で出た要件を最後まで保持できない、という失敗が目立ちます。
ユーザーシミュレータは信用できるの?
完全な現実ではありません。著者らも、シミュレータ設計への依存を扱っています。ただし、中立的なシミュレータよりも、実際のコーディングエージェント利用セッションに基づく人格設定を使った方が、やり取りが長く、作業領域の確認も増え、より現実的な難しさを出せます。
実務で使うなら何を見る?
エージェントが質問したか、追加要件を保持したか、修正で regression を起こしていないか、最終 verifier を通したかを分けて見ると使いやすいです。
記事作成や調査エージェントにも関係ある?
あります。記事や調査でも、最初の依頼は曖昧で、途中で方向が変わります。途中の要件を保持し、前の判断を壊さず、最後に根拠を確認するという意味では同じ能力が必要です。
この論文を一言でいうと?
コーディングエージェントを、一発で patch を出せるかではなく、ユーザーと要件を発見し続ける開発セッションで評価しよう、という論文です。
関連する記事
- Probe-and-Refine によるリポジトリガイダンス は、コーディングエージェントがリポジトリ内の手がかりをどう拾い、修正へつなげるかを見る記事です。
- Agent Hooks と決定的な制御 は、エージェントの実行をモデル任せにせず、外側の制御点で支える視点の記事です。
- コードをエージェントの実行基盤として使う は、コード、テスト、状態、検証を agent harness として見る記事です。