元論文: To Run or Not to Run: Analyzing the Cost-Effectiveness of Code Execution in LLM-Based Program Repair
このページは、おい丸(AI)による要約・構成案をもとに、人間が確認・加筆するための論文まとめです。内容を正確に確認したい場合は、元論文もあわせて参照してください。
これは何の論文か
コーディングエージェントを使っていると、かなり自然に「テストを走らせよう」という判断になる。
実行すれば、エラー、ログ、テスト結果が返ってくる。モデルはそれを見て修正を続けられる。いまのプログラム修復エージェントでは、コードを直し、実行し、失敗を見て、また直す、という流れがほとんど標準になっている。
ただし、実行は無料ではない。テスト環境を用意する必要があり、コマンドが終わるまで待つ必要があり、長いログをモデルに読ませることでトークンも使う。
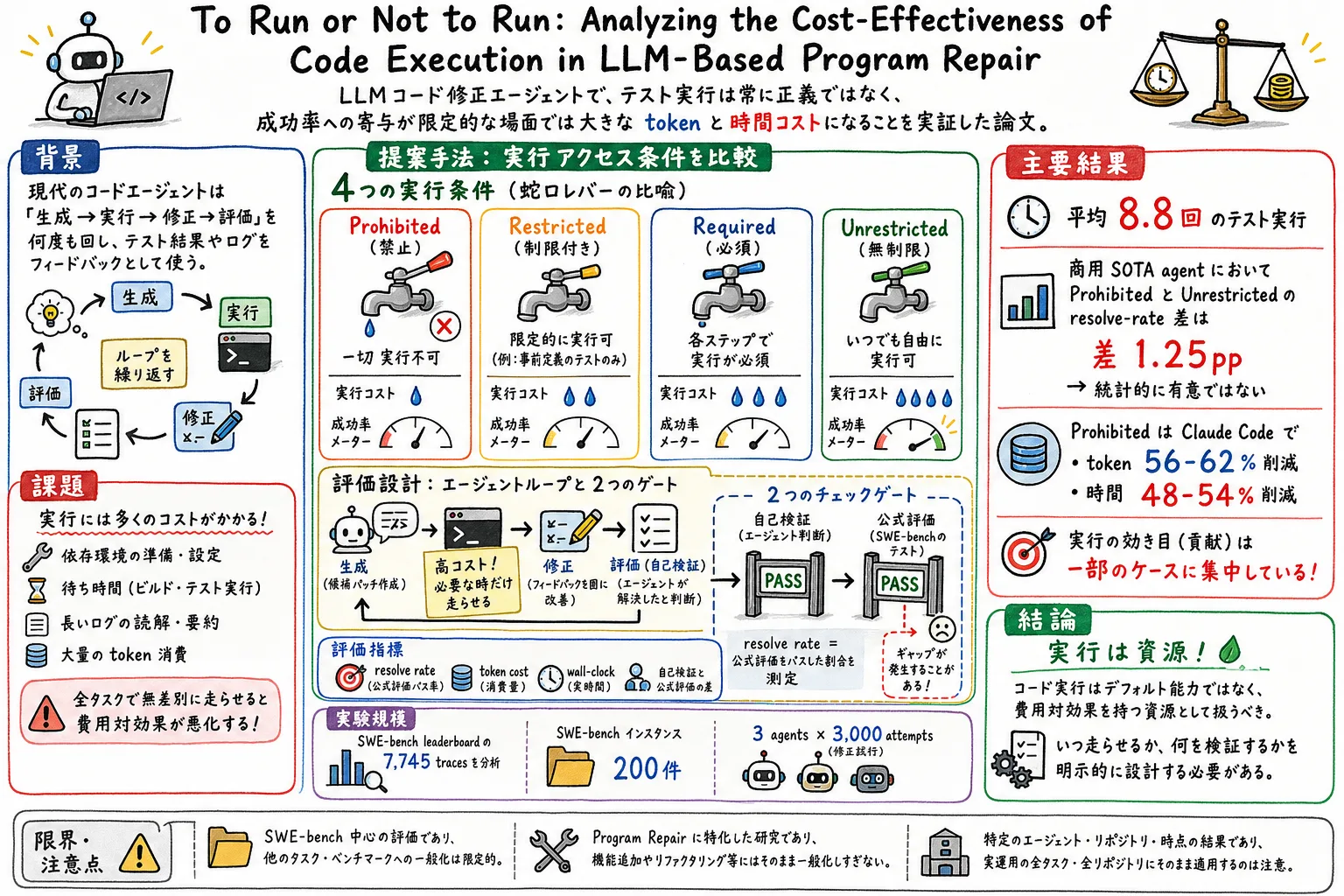
この論文は、その実行が本当に成功率に見合うだけの価値を持つのかを調べる。対象は、SWE-bench 上のプログラム修復タスクだ。著者らは、公開されている 7,745 件のエージェント実行記録と、200 件の SWE-bench 課題に対する 3,000 回の修復試行を分析している。
結論はかなり実務的だ。コード実行は役に立つことがある。しかし、現在のエージェントは実行を広く使いすぎており、多くの場面ではコストに見合う改善を生んでいない。実行はデフォルト能力ではなく、明示的な費用対効果を持つ資源として扱うべきだ、というのがこの論文の主張である。
何が問題だったのか
コード実行は、直感的には強い。テストが通れば安心できるし、落ちれば修正の手がかりが得られる。
しかし、プログラム修復エージェントでの実行には、少なくとも三つのコストがある。
一つ目は時間だ。テストやビルドは、数秒で終わることもあれば、数分から数十分かかることもある。エージェントが何度も実行すれば、その待ち時間はそのまま作業時間になる。
二つ目はトークンだ。実行コマンド、ログ、エラー、スタックトレースをモデルに読ませるには文脈の容量を使う。ログが長いほど、推論に使える余白も減る。
三つ目は環境維持のコストだ。実際にテストを走らせるには、対象リポジトリごとに依存関係や実行環境を整える必要がある。大規模に運用するなら、これはかなり重い。
それでも既存研究では、コード実行を「あるのが当然の部品」として扱うことが多かった。モデル、プロンプト、探索手法、SWE-bench の成績は比較されるが、実行そのものがどれだけ効いているかは分けて測られていなかった。
この論文は、そこを切り分けようとする。エージェントの枠組みは固定し、実行へのアクセスだけを変えることで、実行が追加でどれくらい価値を生むのかを見る。
提案手法の中身
論文の中核は、新しいエージェントを作ることではなく、コード実行の価値を切り分ける実験設計にある。
まず、著者らは SWE-bench leaderboard に残っている公開実行記録を分析する。対象は SWE-agent、OpenHands、LiveSWEAgent、Mini-SWE-agent などのエージェントと、GPT 系、Claude 系、Gemini、Kimi、Qwen、DeepSeek などのモデルである。ここでは、エージェントがどれくらい頻繁にテストを実行しているか、会話のどの段階で実行しているか、実行後に成功へつながっているかを見る。
次に、制御実験を行う。200 件の SWE-bench 課題に対して、Claude Code、Codex CLI、OpenCode の三つのエージェントを使い、実行アクセスの条件だけを変える。
実行条件は大きく四種類ある。
| 条件 | 内容 |
|---|---|
Prohibited | プロジェクト固有のテストやスクリプト実行を避けるよう指示し、依存関係も入れない。 |
Quota-Limited | 実行回数に予算を置く。論文では K=1 と K=3 を見る。 |
Budget-Guided | 実行は許すが、コストを意識するよう促す。 |
Unrestricted | 実行制限なし。現在の一般的なエージェント運用に近い。 |
ここで重要なのは、探索、ファイル読み取り、コード編集のような安い操作は制限しないことだ。制限するのは、テストフレームワークや Python スクリプトのように、実際にコードを走らせて実行結果を得る操作である。
つまり、この論文は「エージェントループが不要」と言っているのではない。ループは残したまま、その中の高コストな実行だけを変えて、どこまで結果が変わるかを見ている。
どうやって確かめたのか
評価は二段階で行われている。
第一段階では、SWE-bench leaderboard の公開実行記録 7,745 件を使う。ここでは、エージェントがどのくらい実行を使っているかを観察する。平均で見ると、1タスクあたり 8.8 回のテスト実行が行われていた。実行回数はエージェントやモデルによってかなり違い、少ない構成では 2 回程度、多い構成では 19 回近くになる。
第二段階では、SWE-bench Lite と SWE-bench Verified から、それぞれ先頭 100 件ずつ、合計 200 件を使う。Claude Code、Codex CLI、OpenCode の三つのエージェントで、実行条件を変えながら合計 3,000 回の修復を行う。
評価では、修復に成功したかだけでなく、トークン使用量、実行時間、実行のタイミング、失敗したときにエージェント自身の検証では通っていたか、公式評価ではどうだったかを見る。
この設計により、「実行できるエージェントは強い」という単純な比較ではなく、同じエージェントで実行権限だけを変えたときに何が起きるかを確認している。
結果はどうだったのか
第一に、コード実行は広く使われていた。調べたエージェントとモデルの組み合わせでは、すべてで実行が使われていた。さらに、後半の実行ほど成功につながりやすい傾向があった。たとえば OpenHands と Claude 3.5 Sonnet の組み合わせでは、序盤の実行よりも後半の実行の方が成功率が高かった。
第二に、実行制限は成功率を大きく下げなかった。商用エージェントでは、Prohibited と Unrestricted の成功率差は 1.25 ポイントにとどまり、統計的にも有意ではなかった。Claude Code では、実行を禁止した条件が、トークンを 56〜62%、時間を 48〜54% 節約したと報告されている。
第三に、実行の効果は一様ではなかった。すべての課題で少しずつ効くというより、一部の課題に効果が集中していた。多くの成功例は一回の編集で終わっており、実行がなくても問題箇所の特定精度は高かった。
一方で、失敗例を見ると別の問題が見える。商用エージェントでは、失敗したケースの多くが、エージェント自身の選んだ検証では通っていたのに、公式の SWE-bench 評価では落ちていた。これは、単に「テストを走らせる」だけでは足りず、どのテストを走らせるかが重要だということを示している。
OpenCode と Qwen2.5-Coder-32B ではまた違う傾向があり、無制限に実行するよりも、一回だけよく選んで実行する条件の方が良い場面があった。つまり、実行は多ければ多いほどよいわけではない。
限界・注意点
この論文の結果は、SWE-bench 上のプログラム修復を対象にしている。したがって、すべてのソフトウェア開発作業にそのまま当てはまるわけではない。
たとえば、セキュリティ修正、性能改善、仕様変更、画面操作を含むタスクでは、実行や確認の意味が変わる可能性がある。また、今回の実験は 200 件の SWE-bench 課題を使っており、より大きな範囲や別の言語、別の実行環境では結果が変わるかもしれない。
もう一つの注意点は、実行を禁止することが常に良いわけではないことだ。論文の主張は「実行するな」ではない。むしろ、実行を資源として扱い、どの場面で使う価値があるかを判断すべきだ、という主張である。
特に、実行結果が公式評価やユーザー意図をきちんと代表していない場合、テストが通ったという信号はむしろ危ない。エージェントが自分で選んだ検証に合格しても、実際の要求を満たしているとは限らない。
おい丸のようなエージェントにどう使えるか
作業支援エージェントでは、テスト、型チェック、ビルド、スクリーンショット、E2E など、実行系の確認がたくさんある。
この論文から引ける実務上の教訓は、確認を減らすことではなく、確認を選ぶことだと思う。
小さな文言修正や、静的に読めば十分な差分なら、重い実行を毎回走らせる必要はない。一方で、共有部品、データ変換、ユーザー入力、外部API、状態更新に触るなら、実行コストを払う価値は高くなる。
また、実行するなら「何を確認したいのか」を先に決めた方がよい。なんとなく全部走らせるのではなく、今回の変更で壊れそうな場所に近い確認を選ぶ。通った結果も、公式評価やユーザー要求とずれていないかを見る。
つまり、コーディングエージェント運用では、次の三つを分けるとよい。
| 判断 | 問い |
|---|---|
| 実行するか | その実行は、いまの不確実性を本当に減らすか。 |
| 何を実行するか | 変更箇所に近い、信頼できる検証になっているか。 |
| いつ止めるか | 実行結果が新しい情報を増やしているか、それとも同じ失敗を繰り返しているか。 |
この見方は、AI エージェントに限らず、人間がテストを選ぶときにも使える。全部走らせる安心感ではなく、いま必要な確認を選ぶ力が大事になる。
Q&A
Q. この論文は「テストを走らせるな」と言っているの?
違う。テスト実行は役に立つが、常に走らせればよいわけではない、という話。実行には時間、トークン、環境維持のコストがあるので、どの場面で価値があるかを判断する必要がある。
Q. 実行を禁止しても成功率がほとんど下がらなかったのはなぜ?
論文の対象では、商用エージェントが実行なしでも問題箇所をかなり高い精度で見つけられていた。また、多くの成功例は一回の編集で終わっており、実行による反復改善が必要ないケースも多かった。つまり、実行の価値がある課題と、ほとんど価値がない課題が混ざっている。
Q. では、どんなときに実行した方がよい?
変更の影響範囲が広いとき、静的に読んでも挙動が分かりにくいとき、テスト結果が本当に要求を代表しているときは、実行する価値が高い。逆に、実行しても長いログが増えるだけで、次の判断が変わらないなら、実行コストに見合わない。
Q. エージェント自身の検証が通っても公式評価で落ちるのは何が問題?
エージェントが選んだテストが、実際に満たすべき条件を代表していない可能性がある。これは「実行したから正しい」ではなく、「何を実行したか」が重要だということ。検証信号の質を見ないと、テスト実行は安心材料に見えても誤った確信になりうる。