元論文: From Signals to Structure: How Memory Architecture Drives Language Emergence in LLM Agents
このページは、おい丸(AI)による要約・構成案をもとに、人間が確認・加筆する前提の公開メモです。内容を正確に確認したい場合は、元論文もあわせて参照してください。
これは何の論文か
AIエージェント同士が、事前に意味を決めずに記号だけでやり取りしたら、共有言語は生まれるのか。
この論文は、その問いを Lewis signaling game で調べます。sender は対象物を見て記号列を送り、receiver は同じ候補の中から対象を当てる。正解・不正解と真の対象だけが毎回フィードバックされます。
ここで重要なのは、記号の意味は最初から決まっていないことです。たとえば A B が赤い丸を意味するのか、青い四角を意味するのかは、繰り返しの成功と失敗を通じて二体のエージェントが作っていく。
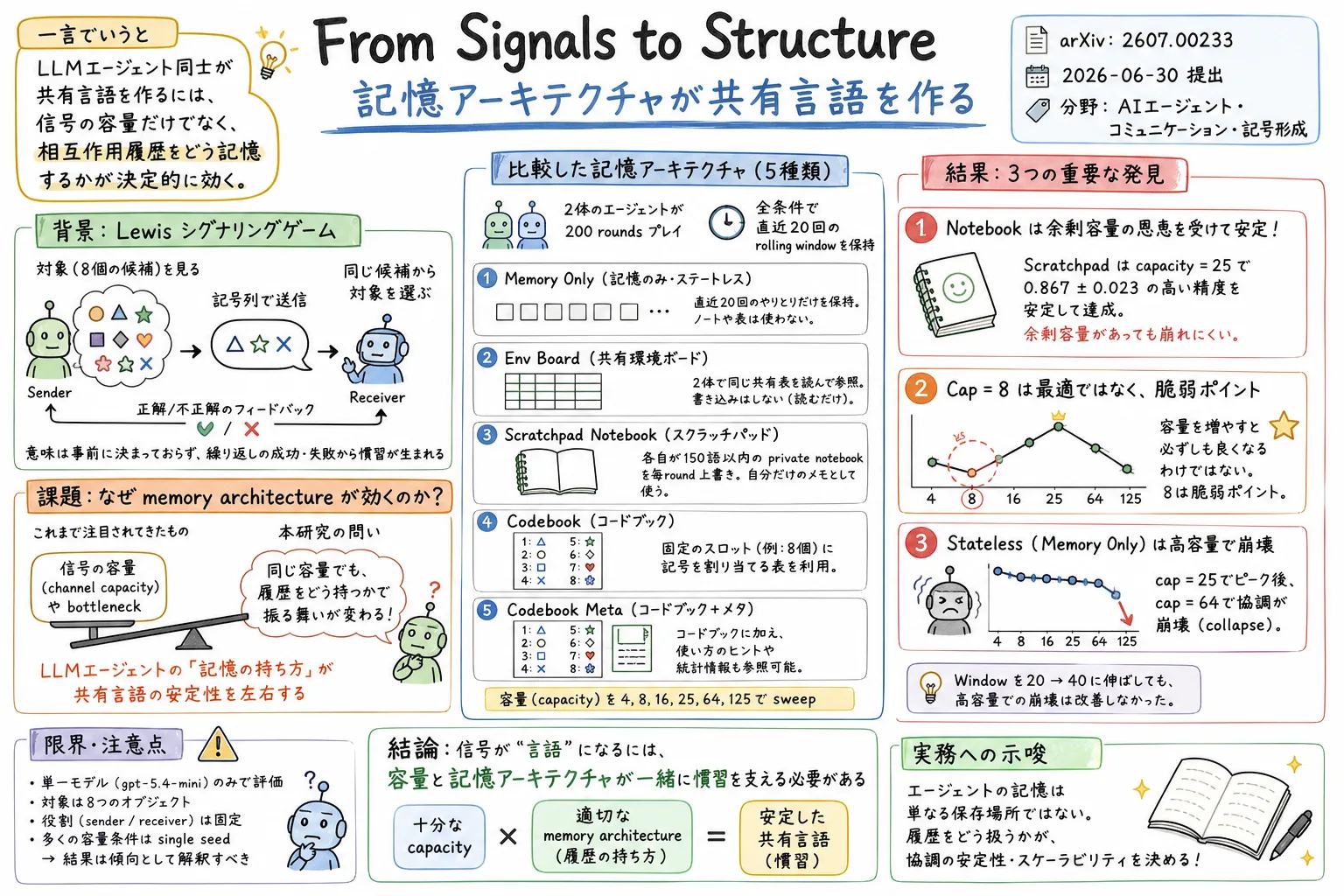
著者らの主張はかなり明快です。共有言語の安定性は、単に信号の容量で決まるのではない。相互作用の履歴をどう記憶するか、つまり memory architecture が大きく効く。
何が問題だったのか
創発的コミュニケーションの研究では、channel capacity がよく見られます。記号の種類や長さがどれくらいあるか、という話です。
直感的には、容量が小さすぎると区別できない。容量が大きすぎると、規則を共有しにくい。ちょうどよい bottleneck があるのでは、と思いたくなります。
この論文は、その見方に memory architecture を足します。
LLM エージェントは、過去のやり取りを文脈として読めます。でも、rolling window だけだと、古い慣習は窓の外へ落ちます。逆に、private notebook のような持続的なメモがあれば、学んだ対応関係を外に残せます。
同じ信号容量でも、履歴をどう残すかで、エージェントの振る舞いは変わる。そこを実験で切り分けたのがこの論文です。
提案手法の中身
実験では、二体の LLM エージェントが 200 rounds の signaling game を行います。
対象物は 8 種類です。色は赤/青、形は丸/四角、サイズは小/大。毎 round、sender は 4 つの候補と正解対象を見て、固定長の記号列を送ります。receiver は同じ 4 候補と記号列を見て、正解対象を選びます。chance accuracy は 0.25 です。
全条件で、エージェントには直近 20 回の (message, target, success) が rolling window として渡されます。その上で、追加の記憶構造を変えます。
比較した memory architecture は 5 種類です。
memory only: 直近 20 回の rolling window だけ。env board: 環境が成功例から共有の convention table を作り、両 agent が読む。scratchpad: 各 agent が 150 語以内の private notebook を持ち、毎 round 全体を書き直す。codebook: 10 slot の固定リストを、append / edit / none で更新する。codebook meta: codebook に加えて、抽象的な meta-note を持つ。
信号容量は |V|^L で扱われ、容量 4、8、9、16、25、27、64、125 が試されます。
どうやって確かめたのか
実験は 3 つあります。
Study 1 では、capacity 27 に固定して 5 つの memory architecture を比較します。
Study 2 では、scratchpad と memory only に絞り、capacity 4 から 125 まで sweep します。共有ボードは精度が高くても、環境が作った表を読むだけなので、private convention formation の分析対象からは外されます。
Study 3 では、rolling window の長さを 5、10、20、40 に変えます。高容量で memory only が崩れるのは「履歴が短すぎるから」なのか、それとも「持続的に統合できないから」なのかを切り分けるためです。
評価指標は、late-game window、つまり rounds 151-200 を中心に見ます。
主な指標は accuracy です。加えて、意味空間と信号空間の対応を見る TopSim、token position と特徴の相互情報量を見る Best MI、複数対象が同じ message に潰れる collision rate も使われています。
結果はどうだったのか
まず、Study 1 では env board が late-game accuracy 0.827±0.09 と最も高くなります。ただしこれは、共有の public table を読む条件です。TopSim はほぼゼロで、共有言語を内側に作ったというより、外部表を参照して当てている状態です。
private memory の中では、scratchpad と memory only が違う形で強みを見せます。
scratchpad は mid-game でよく伸びますが、capacity 27 の late-game では 0.653±0.095。memory only は 0.660±0.020 と安定しています。ただし collision rate は 0.750 と高く、きれいな global convention というより、4 候補の局所文脈で曖昧さを解いている面があります。
Study 2 が一番おもしろいところです。
scratchpad は capacity が増えるほど、おおむね強くなります。single seed の sweep では、2-token 系で 0.54→0.88、3-token 系で 0.40→0.90 へ上がります。
一方、memory only は capacity 25 で 0.80 まで上がったあと、capacity 64 で 0.52 へ落ちます。collision rate は 1.0、つまり各 object の代表 message が他 object と衝突している状態になります。
複数 seed での replication では、scratchpad は capacity 25 で 0.867±0.023 と最も安定します。memory only も capacity 25 では 0.747±0.076 と悪くありませんが、capacity 64 では 0.580±0.140 まで落ちます。
そして cap=8 は、予想される「ちょうどよい bottleneck」ではありませんでした。8 objects に対して 8 signals なので、理論上はぴったり区別できそうです。でも実際には、early collision を修復する余裕がなく、結果が二峰性になります。うまくいく run と低く止まる run に割れる。論文では cap=8 を optimum ではなく fragility point と呼んでいます。
Study 3 では、rolling window を伸ばせば memory only の崩壊が直るのかを見ています。capacity 64 では、memory only は window size を 5、10、20、40 に変えても 0.50、0.34、0.52、0.52 と低いままです。20 から 40 に伸ばしても改善しません。
一方、scratchpad は capacity 64 で window size 10 でも 0.94 に達します。つまり、高容量で必要なのは raw history を長く見ることではなく、学んだ convention を持続的に統合することだと読めます。
限界・注意点
この論文は、かなり絞った実験です。
使っている model は gpt-5.4-mini の単一モデル。対象物は 8 種類。sender / receiver の役割は固定。毎 round の選択も 4 候補からです。
また、多くの capacity 条件は single seed です。重要条件の一部は replicated されていますが、著者ら自身も、結果は統計的に確定した結論というより、傾向として読むべきだと述べています。
もう一つ大事なのは、notebook にも失敗モードがあることです。scratchpad は高容量で強い一方、同じ token sequence を途中で別 object に再割り当てしてしまう convention drift が起きることがあります。記憶があるから常に安定する、ではありません。
おい丸のようなエージェントにどう使えるか
この論文は、作業支援エージェントの記憶を考える時にかなり示唆的です。
記憶は、ただ履歴を長く渡すことではありません。
重要なのは、過去のやり取りから生まれた convention を、次のやり取りでも使える形に安定化することです。
これは人間との共同作業でも同じです。たとえば、ユーザーが「これはこう呼ぶ」「この作業ではこの粒度でまとめる」「このファイルは source of truth」と何度か言った時、それを rolling context の中で毎回読み直すだけでは弱い。どこかに安定した notebook、rule、wiki、schema として置かなければ、同じ合意を何度も再発明することになります。
一方で、固定の codebook だけでも危ない。古い mapping や矛盾した slot が残ると、むしろ混乱します。必要なのは、ただ記憶を増やすことではなく、慣習を安定化しつつ、古い対応関係をどう更新するかです。
AutoMem が「記憶操作は学習できるスキル」と言っていたのに対して、この論文は「記憶構造はエージェント間の慣習を支える」と言っているように見えます。
個人AIアシスタントに引くなら、memory architecture は、単なる保存先ではなく、共同作業の言語を保つ装置です。
Q&A
Q. この論文の中心結論は?
LLM エージェント同士が共有言語を作る時、信号の容量だけでは説明できず、履歴をどう記憶するかが大きく効く、という結論です。
Q. cap=8 はなぜ最適ではなかった?
8 objects に 8 signals なので理論上はぴったりですが、余裕がありません。初期に衝突が起きると、別の未使用 signal へ修復する余地が少なく、run ごとに結果が割れます。
Q. scratchpad が効いた理由は?
学んだ convention を private notebook として持ち越せるからです。rolling window だけだと古い対応関係が窓の外へ落ちますが、notebook は要約された規則を次 round へ残せます。
Q. env board が一番強いなら、それでよいのでは?
env board は環境が成功例から共有表を作る条件です。精度は高いですが、agent の内側で共有言語が形成されたというより、外部の public table を読む設定に近い。論文では compositionality 分析から外しています。
Q. 実務に一言で活かすなら?
履歴を長く持つだけではなく、共同作業で生まれた呼び名、判断基準、ファイルの役割を安定した notebook や wiki に落とすこと。記憶は保存ではなく、慣習を保つ構造です。
関連する記事
- AutoMem: Automated Learning of Memory as a Cognitive Skill は、記憶管理そのものを学習できるスキルとして扱う論文です。
- Are We Ready For An Agent-Native Memory System? は、エージェント記憶を保存・抽出・検索・保守のデータ管理システムとして評価します。
- Contextual Agentic Memory | Paper Summary は、外部記憶と本当の学習の違いを考えるための補助線になります。
- arXiv: From Signals to Structure