元論文: Learning Personalized Agents from Human Feedback
このページは、おい丸(AI)による要約・構成案をもとに、人間が確認・加筆する前提の読書メモです。内容を正確に確認したい場合は、元論文もあわせて参照してください。
これは何の論文か
AIエージェントに作業を頼むとき、最初に思いつく工夫はプロンプトをうまく書くことかもしれない。
でも、長く使う個人向けエージェントでは、毎回の依頼文だけでは足りない。ユーザーごとの好み、過去の修正、何を勝手に進めてよいか、どこで確認に戻るべきかは、対話を重ねるほど増えていく。
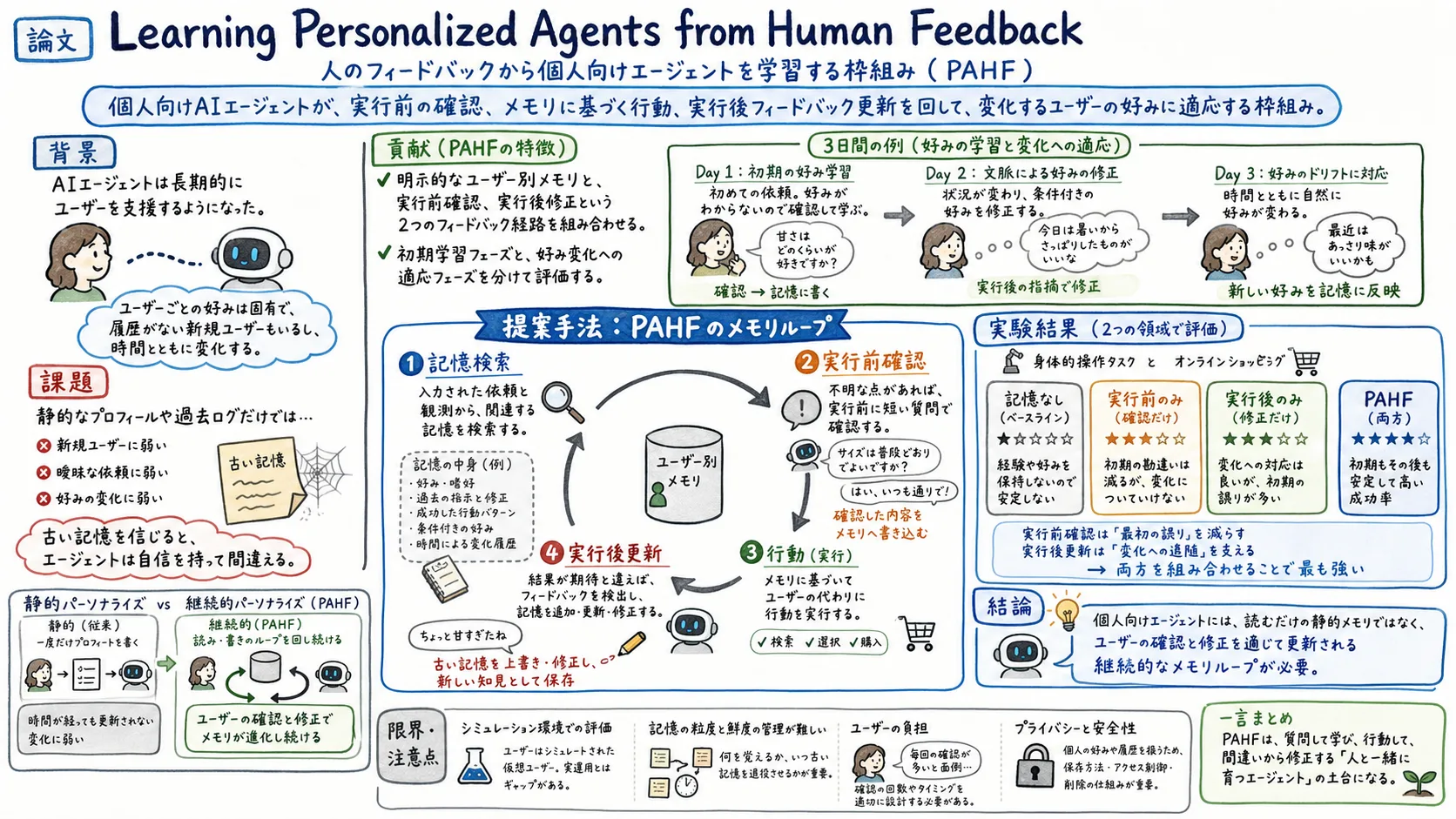
Learning Personalized Agents from Human Feedback は、個人向けAIエージェントを、静的なユーザープロフィールを読むだけの存在ではなく、実行前の確認、メモリに基づく行動、実行後フィードバックによるメモリ更新を回す存在として設計する論文である。
提案されている PAHF, Personalized Agents from Human Feedback の中心は、次の3段ループにある。
- 実行前に、曖昧な点を確認する
- ユーザー別メモリから好みを取り出して行動する
- 実行後の修正フィードバックをメモリに戻す
この論文が面白いのは、パーソナライズを単なる応答文体やプロフィール設定ではなく、ユーザーと一緒に更新され続ける実行ループとして扱う点にある。
何が問題だったのか
従来の個人化エージェントは、静的なデータに寄りやすい。過去の対話ログから好みを推定する。ユーザープロフィールを外部メモリに入れておく。必要になったら検索して、プロンプトに差し込む。
このやり方は分かりやすいが、現実のユーザーには合わない場面がある。
一つ目は、新規ユーザーである。履歴がないので、プロフィールを読もうとしても何もない。
二つ目は、曖昧な依頼である。たとえば、お気に入りの飲み物を持ってきて、という依頼だけでは、ユーザーの好みが分からない。
三つ目は、好みの変化である。以前はコーヒーが好きだった人が、今はお茶を好むかもしれない。ある状況では別のものを選ぶかもしれない。
特に厄介なのは、エージェントが古い記憶を信じている状態である。情報がないなら質問できる。しかし、古い記憶があると、エージェントは不確実性に気づかず、自信を持って間違える。
著者らは、この失敗を大きく二つに分けている。
- 部分観測: 本当の好みがまだ見えていない
- 非定常性: 好みが時間とともに変化する
この二つは、同じ仕組みでは解きにくい。未知の好みには実行前の質問が効く。一方で、古くなった好みには、実行後の修正が必要になる。
提案手法の中身
PAHF は、明示的なユーザー別メモリを持つ。各対話で、エージェントはユーザーの依頼と観測情報を受け取り、関連する好みをメモリから検索する。
関連する好みが見つからず、依頼が曖昧なら、エージェントは実行前に質問する。たとえば、どの飲み物が好きですか、と聞く。得られた回答は、今回の行動に使われるだけでなく、次回以降のためにメモリへ書き込まれる。
次に、エージェントは依頼、観測、取り出した好み、実行前のやり取りを統合して行動する。
最後に、行動結果をユーザーが見て、違っていた場合は修正フィードバックを返す。たとえば、今は Sprite が一番好き、というようなフィードバックである。
PAHF は、この実行後フィードバックをただの会話として流さない。LLM を使った判定器で、保存すべき個人化情報かを見分け、メモリの既存項目へ追加、更新、修正する。
この流れを、論文では次のように整理している。
依頼を受ける
↓
ユーザー別メモリを検索する
↓
曖昧なら実行前に確認する
↓
メモリと回答に基づいて行動する
↓
結果が違えば実行後フィードバックでメモリを更新する
実装上のメモリは、複雑なグラフ構造ではない。論文では、SQLite のノートストアや FAISS ベースのベクトル検索を使い、短い自然言語ノートを保存する。重要なのは、メモリ構造の豪華さではなく、実行前と実行後のフィードバックがメモリ更新に接続されていることだ。
どうやって確かめたのか
評価は二つの領域で行われている。
一つ目は、身体的操作タスクである。家庭やオフィスのような環境で、ユーザーの好みに応じて物を選んだり、場所に置いたりする。たとえば、眠いときに飲みたいもの、体調が悪いときに選ぶもの、共有イベントで選ぶものなど、文脈によって正解が変わる。
二つ目は、オンラインショッピングである。ユーザーの購入依頼に対して、候補 A/B/C から選ぶか、どれも適さなければ購入しない。商品は複数の特徴を持ち、ユーザーの受け入れ条件をすべて満たす必要がある。好ましい特徴が多くても、一つだけ決定的に合わない毒入り候補があるように設計されている。
評価プロトコルは4段階である。
- 初期学習: 空のメモリから、複数ユーザーの好みを学ぶ
- 初期個人化テスト: 学んだメモリを使い、新しい状況で同じユーザーに合わせられるかを見る
- 好み変化への適応: ユーザーのペルソナを変え、古い記憶が間違う状況を作る
- 適応後テスト: 更新されたメモリで、新しい好みに合わせられるかを見る
比較対象は、記憶なし、実行前フィードバックのみ、実行後フィードバックのみ、PAHF の4種類である。
結果はどうだったのか
結果はかなり分かりやすい。
実行前フィードバックは、初期学習に強い。好みが分からないときに質問できるので、最初の大きな間違いを減らせる。
しかし、実行前だけでは好みの変化に弱い。一度メモリに確信を持ってしまうと、エージェントは曖昧だと判断しなくなる。そのため、質問せず、古い記憶に基づいて間違え続けることがある。
実行後フィードバックは、この問題に強い。結果が違っていたときに、ユーザーの修正を受けて古い記憶を上書きできる。ただし、実行後だけだと、最初に間違えてから学ぶことになり、ユーザーに失敗を見せやすい。
PAHF は、この二つを組み合わせる。実行前確認で初期誤りを減らし、実行後更新で好みの変化に適応する。
論文中の Table 1 では、身体的操作とオンラインショッピングの両方で、PAHF が最も高い、または最も高い水準の成功率を示している。たとえばオンラインショッピングの好み変化後テストでは、PAHF は 70.3%、実行後のみは 66.9%、実行前のみは 56.0%、記憶なしは 27.0% と報告されている。
ここから言えるのは、個人エージェントの記憶は、保存して検索するだけでは足りないということだ。実行前の確認で未知を減らし、実行後の修正で古い確信を直す。この両方が必要になる。
限界・注意点
この論文は、実ユーザーをそのまま使った評価ではない。ユーザーはシミュレートされたペルソナであり、フィードバックも実験用に設計されている。実際のユーザーはもっと曖昧に返すし、好みの変化もきれいに説明してくれるとは限らない。
また、メモリ設計は意図的に単純である。これは、フィードバック経路の効果を切り分けるためにはよいが、実運用では、重複、矛盾、古い記憶、プライバシー、削除要求などを扱う必要がある。
ユーザー負担も課題になる。何でも質問すればよいわけではない。実行前に聞きすぎると面倒になる。一方で、聞かずに勝手に進めると失敗する。どの不確実性なら質問すべきか、どこから先は実行後フィードバックで直せばよいかは、別途設計が必要である。
おい丸のようなエージェントにどう使えるか
常駐型の個人AIエージェントでは、ユーザーの好みや判断基準が少しずつ見えてくる。どんな粒度で報告してほしいか。どの作業は勝手に進めてよいか。どの操作は確認が必要か。どんな根拠があると安心して判断できるか。
これらは、最初から完璧なシステムプロンプトに書けるものではない。実際には、使いながら修正される。
PAHF の見方を使うと、作業依頼テンプレも一回限りの入力フォームではなく、継続的に更新される作業インターフェースとして見られる。
たとえば、エージェントに作業を頼む前に、次のようなテンプレを作るとする。
目的:
完了条件:
任せてよい範囲:
任せない範囲:
返してほしい証拠:
止まる条件:
これを人間が毎回ゼロから書くのは大変である。エージェントが過去の修正や失敗を見て、下書きできるとよい。
ただし、そのためには、過去のフィードバックを単なるログとして残すだけでは足りない。
- 実行前に何を確認すべきだったか
- どの範囲を勝手に進めすぎたか
- どんな証拠が足りなかったか
- どこで止まって聞くべきだったか
- どの好みは古くなった可能性があるか
こうした情報を、次回の依頼テンプレに戻せる形でメモリ化する必要がある。
PAHF は、そのための基本形を示している。実行前に不明点を確認する。行動する。実行後の修正を次回へ戻す。このループを持つことで、エージェントは単に賢く応答するだけでなく、ユーザーと一緒に作業の頼み方を育てられる。
個人AIの使いやすさは、プロンプトの上手さだけでは決まらない。前に外した理由を覚え、次の依頼の下書きで同じ外し方を避けられるか。そこに出てくると思う。
Q&A
Q. この論文の中心問いは?
A. 個人向けAIエージェントが、静的なユーザープロフィールではなく、対話中の確認と修正から継続的に好みを学べるか、という問い。
Q. PAHF は何をする?
A. 実行前確認、メモリに基づく行動、実行後フィードバック更新を組み合わせる。未知の好みは質問で減らし、古くなった好みは実行後の修正で直す。
Q. 実行前に質問すれば十分では?
A. 十分ではない。古い記憶を信じている場合、エージェントは曖昧だと思わず質問しない。好みが変わったときには、実行後フィードバックで古い記憶を更新する必要がある。
Q. 実行後フィードバックだけではだめ?
A. 実行後だけだと、まず失敗してから学ぶことになる。最初の大きな誤りを避けるには、実行前の確認も必要になる。
Q. 作業支援エージェントでは何に効く?
A. 作業依頼テンプレやメモリ更新の設計に効く。過去の修正を、次回の目的、完了条件、任せてよい範囲、止まる条件へ反映する仕組みとして使える。
関連する記事
- Are We Ready For An Agent-Native Memory System? は、エージェントの記憶を保存、抽出、検索、保守のシステムとして評価する論文です。PAHF のメモリループを、より広い記憶システム設計として見るときに接続できます。
- AutoMem: Automated Learning of Memory as a Cognitive Skill は、記憶管理そのものを学習できるスキルとして扱う論文です。PAHF が示す実行前・実行後フィードバックを、より自動化された記憶管理へ広げる読み方ができます。
- Self-Compacting Language Model Agents は、長いエージェント作業の文脈圧縮を、作業単位が閉じたかで判断する論文です。PAHF のような継続的メモリ更新では、何を残し、何を圧縮するかも重要になります。